
Ich dachte: 16 GB + externe SSD reichen für Ollama und sparen Geld. Dann wurde der Mac mini mein Alltagsrechner — Chrome mit ~20 Tabs, VS Code, Slack und dauerhaft qwen3:8b. Innerhalb einer Woche wurde der Speicherdruck gelb, Swap blieb bei etwa 1 GB. Die Kollegin mit 24 GB, gleiches Modell, gleiches Skript: grüne Anzeige.
Kein Spec-Sheet-Artikel, sondern sieben Tage Gegenüberstellung zweier M4 Mac mini (16 / 24 GB): was gemessen wurde, wie, und woher die Zahlen stammen. Dazu Qwen3, DeepSeek R1, Gemma 3 für 2026 — und was passiert, wenn OpenHuman, Claude Code oder MLX dazukommen.
Wochentest: gleiche Last mit qwen3:8b
Hardware: Mac mini M4 (10-Core CPU / 10-Core GPU), je eine Maschine mit 16 GB und 24 GB Unified Memory, gleiche macOS- und Softwarestände. Zeitraum: 26.05.–01.06.2026, täglich 2 Stunden „Entwicklung + Chat“, jede Kennzahl 3× gemessen, Median.
Gemeinsame Umgebung (realer Desktop, kein Lab-Benchmark):
- macOS 16 (26.x Beta-Kanal, gleicher Build auf beiden)
- Ollama 0.12.3 (
ollama --version) - Google Chrome: 20 Tabs (Notion, GitHub, Gmail)
- Visual Studio Code inkl. Sprachpakete
- Slack Desktop dauerhaft im Hintergrund
Inferenz (Werte nach 5 Minuten Steady State):
ollama pull qwen3:8b ollama run qwen3:8b # Zweites Terminal: 512-Token-Prompts, nach 2 Min Generierung Memory/Swap ablesen
M4 Mac mini mit 16 GB
| Kennzahl | Wert | Hinweis |
|---|---|---|
| Belegter Speicher | 13,2 GB | Aktivitätsanzeige → Speicher → „Belegt“ |
| Swap | 1,1 GB | Gelber Speicherdruck, Lüfter gelegentlich hoch |
| Generierung | 34 tok/s | siehe ollama run --verbose |
| Subjektiv | Chrome scrollt ruckelig | bei hohem Swap, nicht dauerhaft |
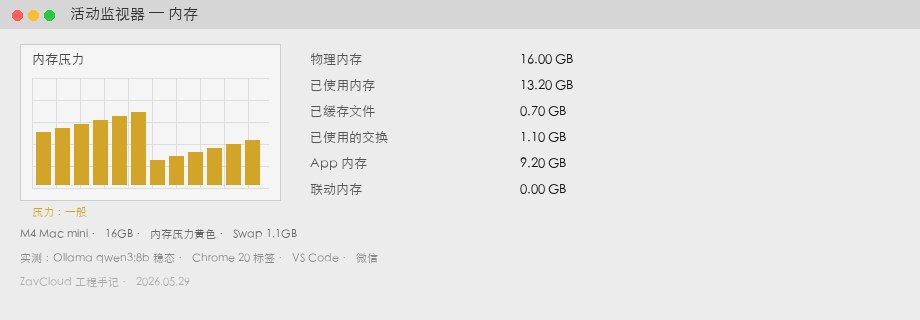
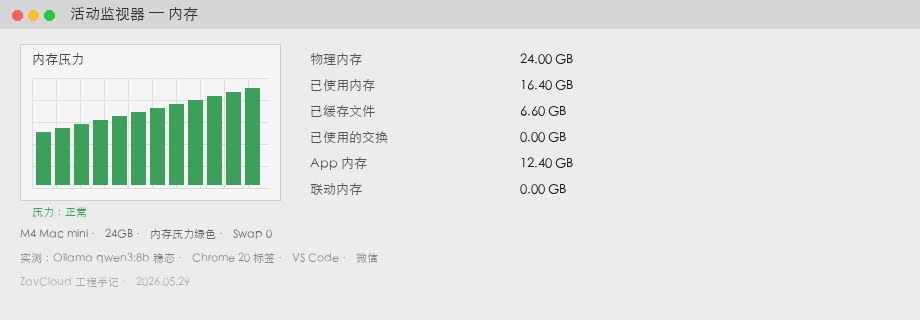
qwen3:8b im Steady State + Chrome / VS Code / Slack. 13,2 GB belegt, 1,1 GB Swap, gelber Druck.M4 Mac mini mit 24 GB
| Kennzahl | Wert | Hinweis |
|---|---|---|
| Belegter Speicher | 16,4 GB | gleiche Last, gleiches Modell |
| Swap | 0 GB | grüner Speicherdruck |
| Generierung | 37 tok/s | ähnliche GPU-Last, Unterschied vor allem ohne Swap |
| Reserve | ca. 7,6 GB | z. B. nomic-embed oder zweites 3B-Modell |
Was heißt „falsche Variante“?
Nicht, dass 16 GB Ollama verbietet, sondern dass meine echte Last kein Einzel-Task-Lab ist. Wer nur API-Proxy und gelegentlich ollama run nutzt, bleibt bei 16 GB. Wer Standard-Desktop „Browser + IDE + Qwen3/DeepSeek + Agent“ will, ist mit 24 GB entspannter.
So entstehen die Zahlen (reproduzierbar)
Alle Tabellenwerte folgen diesem Ablauf — auf Ihrer Maschine in einem halben Tag nachvollziehbar:
- Gewichtsgröße —
ollama show qwen3:8b --modelfileund*.ggufim Modellordner (Disk ≠ RAM, aber Untergrenze). - Steady-State-RAM — nach Laden: Aktivitätsanzeige → Belegt / Swap / Speicherdruck.
- tok/s — fester 512-Token-Prompt,
--verbose, eval rate:
ollama run qwen3:8b --verbose \ "Erkläre Apple Unified Memory auf Deutsch in ~400 Wörtern, drei Vor- und Nachteile." # eval rate (tokens/s) dreimal mitteln vm_stat | awk '/swap/ {print}' memory_pressure
Nicht fixiert: Ollama-Version und Quantisierung (Q4_K_M vs Q5) verschieben 0,5–1,5 GB. Gemma 3 / DeepSeek R1 nach eigenem ollama pull messen. 14B-Zeilen unten mit derselben Methode.
Beliebte Modelle auf M4 Mac mini (2026)
✅ Alltagstauglich mit obiger Last; ⚠️ läuft, aber Swap / Apps schließen; ❌ nicht als Hauptmodell.
| Modell (Ollama-Tag) | 16 GB | 24 GB | Wochentest |
|---|---|---|---|
Qwen3 8B qwen3:8b |
✅ | ✅ | 16 GB: ~1,1 GB Swap; 24 GB: 0 Swap |
DeepSeek R1 8B deepseek-r1:8b |
✅ | ✅ | Gewichte ~5,2 GB; Kurve wie Qwen3 8B |
Qwen3 14B qwen3:14b |
⚠️ | ✅ | 16 GB: Swap 2,3 GB+ |
| Gemma 3 27B (quantisiert) | ❌ | ⚠️ | 24 GB nur Spielwiese; längerer Kontext → OOM |
| Llama 3.2 3B | ✅ | ✅ | gut als Embed-/RAG-Sidecar |
Mit MLX ähnliche Größenordnung, aber spitzere Peaks bei Compile + Xcode — 5 Minuten Steady State in der Aktivitätsanzeige, nicht nur Parameterzahl auf der Modellkarte.
14B und DeepSeek (gleiche Desktop-Last)
Nur das Ollama-Modell getauscht, Chrome / VS Code / Slack unverändert:
| Modell | RAM | Belegt | Swap | tok/s |
|---|---|---|---|---|
deepseek-r1:8b |
16 GB | 13,5 GB | 1,0 GB | 33 |
deepseek-r1:8b |
24 GB | 16,6 GB | 0 | 36 |
qwen3:14b |
16 GB | 15,8 GB | 2,3 GB | 18 |
qwen3:14b |
24 GB | 19,1 GB | 0 | 28 |
Kurz: Qwen3 / DeepSeek 14B als Dauerbegleiter → 16 GB kämpft mit Swap; 24 GB behält Browser und IDE ohne „Aufräum-Modus“.
Warum „14B Q4 ~8–10 GB“ — und was die Messung zeigt
- GGUF auf Disk —
ollama pull qwen3:14bliefert etwa 8,4–9,2 GB (Quantisierung). - KV-Cache — bei 8k Kontext oft +1–3 GB; größeres
OLLAMA_CONTEXT_LENGTHdrückt 16 GB schneller an die Wand. - Summe gemessen —
qwen3:14bauf 24 GB: 19,1 GB belegt = Modell + KV + Chrome/IDE/System (~5–6 GB). Nur-Modell-Anteil ~13–14 GB — passt zu „8–10 GB Gewichte + Laufzeit“.
14B Q4 ist machbar, aber nicht parallel zum vollen Desktop — entweder 24 GB, oder Tabs zu, Kontext runter, Embed auf zweiter Maschine.
Claude Code, OpenHuman — zusätzlicher RAM-Bedarf
- Claude Code + Ollama — Agent über API, Ollama für Offline-Entwürfe. VS Code/Cursor 1–2 GB plus Chrome: auf 16 GB kaum 14B-Reserve.
- OpenHuman +
qwen3:8b— Hintergrundprozesse stabil 1 GB+; Setup in der OpenHuman-Installationsanleitung. Auf 24 GB: OAuth-Sync + 8B ohne Swap. - MLX — mit Xcode/Core ML spitzere Peaks; Batch besser auf dediziertem Core-ML-Cloud-Knoten, 16 GB lokal fürs Coden.
Große Repos mit CodeGraph + Claude Code MCP fressen den Index weniger RAM, aber Sie schließen ungern Chrome — effektiv Richtung 24 GB (CodeGraph lokal).
Kaufempfehlung (aus Messung, nicht aus der Spec-Tabelle)
- 16 GB — nur 8B (Qwen3 / DeepSeek R1), Swap ok, oder Cloud-API-Hauptweg mit Ollama als Backup.
- 24 GB — Standard 14B + Browser + IDE + Agent, Gemma 3 27B zum Ausprobieren, 3–5 Jahre ohne RAM-Engpass am mini.
Der GPU-Cloud-Kostenvergleich bleibt komplementär: RAM löst „eine Maschine bequem“, Cloud löst „7×24 und statische IP“.
M4 Mac mini vs RTX 5060 — welche Route für lokale KI?
Viele vergleichen Apple Silicon Unified Memory mit NVIDIA-VRAM (RTX 5060). ZavCloud betreibt Cloud Mac (exklusive M4 Mac mini) — kein „keine GPU kaufen“, sondern klare Grenzen: Mac vs RTX vs Cloud-GPU.
Mac Studio hebt das RAM-Limit (64 GB+), bleibt Apple-Stack. AWS / Alibaba GPU für 70B, Training, SD-Batches. Tabellen unten mit gleicher Chrome+IDE-Annahme.
Wo der M4 Mac mini gewinnt
| Szenario | M4 Mac mini | Kommentar |
|---|---|---|
| iOS / macOS-Entwicklung | ✅ | Xcode, TestFlight, Gerät — RTX-PC ersetzt das nicht |
| Claude Code / Cursor | ✅ | Terminal-Agent + Ollama-Entwurf; weniger „VRAM OOM“ |
| Lokale KI (8B–14B Text) | ✅ | Qwen3 / DeepSeek 8B–14B; 24 GB ohne Swap |
| OpenHuman / MLX / Core ML | ✅ | Apple-Stack; siehe Core-ML-Cloud |
| AAA-Gaming / CUDA-Training | ❌ | nicht Ziel des Mac mini |
Wo ein RTX-5060-PC gewinnt
| Szenario | RTX 5060 | Kommentar |
|---|---|---|
| PC-Gaming | ✅ | Windows + Dedizierte GPU |
| Stable Diffusion / ComfyUI | ✅ | CUDA-Ökosystem; Mac schwächer |
| 70B quantisiert | ✅ | 12 GB VRAM + System-RAM; 24 GB Mac mini nur ⚠️ für 27B |
| Multi-GPU / Training | ✅ | 5070 Ti, Dual-GPU oder Cloud-GPU; kein CUDA auf Mac |
| App Store-Release | ❌ | Mac nötig — oft „RTX rendern + Cloud Mac paketieren“ |
Hybrid (häufig bei Kunden)
Lokal oder Cloud Mac (24 GB) für Ollama / Claude Code / iOS; RTX oder Cloud-GPU für SD und 70B. Bei Swap-Not auf 16 GB: 14B eine Woche auf 24-GB-Cloud-Mac testen, dann RTX entscheiden. Rechnung: M4-Inferenz vs GPU-Cloud.
Vor dem Kauf: eine Woche messen
- Software listen, die Sie nicht schließen (Tabs, IDE, Messenger, Agent);
- Qwen3 8B + 14B je 30 Minuten mit obigen Befehlen, Swap und tok/s notieren;
- 14B dauerhaft Swap > 1 GB → 16 GB streichen.
Ohne Hardware: gleich konfigurierten Apple-Silicon-Cloud-Mac mieten, Ollama/Agent eine Woche laufen lassen, dann kaufen — oft günstiger als blind upgraden.
Typisch: 16 GB lokal entwickeln + 24 GB in der Cloud für Ollama/OpenHuman. ZavCloud liefert exklusive M4 Mac mini (macOS, statische IP) für Kauf-Drucktests. Details: Mac-mini-Miete & Preise.
- Weiterlesen — M4 vs GPU-Cloud · OpenHuman × Ollama · Claude Code + CodeGraph
FAQ
Zwölf häufige Fragen — Antworten passen zu den Tabellen oben.
Wie viel RAM braucht Qwen3 14B?
Unter gleicher Desktop-Last (Chrome ~20 Tabs, VS Code, Slack): qwen3:14b ~19,1 GB belegt (24 GB); auf 16 GB 15,8 GB + 2,3 GB Swap. Nur Modell: GGUF 8,4–9,2 GB + KV — praktisch 24 GB; 16 GB nur mit geschlossenem Browser und kleinerem Kontext.
Läuft DeepSeek R1 14B?
deepseek-r1:8b auf 16 GB (Swap ~1 GB, 33 tok/s) wie Qwen3 8B. 14B wie qwen3:14b: 24 GB ohne Swap (~28 tok/s), 16 GB dauerhaft Swap ~18 tok/s. 14B als Hauptmodell → 24 GB.
Ist 16 GB bald überholt?
Nicht über Nacht. 2026 ist die Norm „Browser + IDE + 8B + Agent“. 16 GB reicht für 8B, API-first, Tabs schließen. Mit Claude Code / OpenHuman ohne Aufräumen wird 16 GB zum Einstieg, nicht zum Komfort.
Wie lange reicht 24 GB?
Bei 8B–14B Hauptmodellen und 27B-Spielerei etwa 3–5 Jahre Sweet Spot für Desktop + lokaler Agent. 32B+ dauerhaft → Mac Studio / Cloud-GPU (RAM am mini nicht nachrüstbar).
Ollama oder MLX — speichersparender?
Chat: Ollama. GGUF-Footprint stabil, passt zu unseren Aktivitätsanzeige-Werten. MLX spitzere Peaks mit Compile/Xcode — Batch auf eigenem Knoten.
Mac mini oder RTX 5060 für lokale KI?
Text 8B–14B, Claude Code, iOS: M4 Mac mini (24 GB). SD, 70B, Gaming: RTX 5060. Viele nutzen beides.
Reicht 16 GB für Qwen3 8B?
Ja: 13,2 GB, ~1,1 GB Swap, 34 tok/s, gelber Druck. Zero-Swap: 24 GB (16,4 GB, 37 tok/s).
Wie viel schneller ist 24 GB?
qwen3:8b nur ~9 % (34 vs 37 tok/s). Kernnutzen: kein Swap, 14B + zweites kleines Modell.
Gemma 3 27B auf 24 GB?
Nur ⚠️ stark quantisiert; längerer Kontext → OOM. 8B–14B ist die Komfortzone.
Mac Studio nur für KI?
Für 8B–14B + Dev: M4 Mac mini 24 GB günstiger. 64 GB oder mehrere große Modelle → Studio oder erst Cloud Mac zum Verifizieren.
Unsicher bei der RAM-Variante?
8B + 14B je 30 Minuten messen. Ohne Rechner: M4 Mac mini 24 GB in der Cloud eine Woche — spart Fehlkäufe.
Reproduzierbar?
Ja. Ollama 0.12.x, gleiche Last: ±10 % möglich; 16 GB Swap, 24 GB kein Swap, 14B braucht 24 GB bleibt.
Aus der Praxis
RAM unsicher? Erst eine Woche messen
Gleiche Last wie im Artikel (Chrome, IDE, qwen3:8b / qwen3:14b), Swap und Speicherdruck notieren. Für produktionsnahe exklusive macOS-Umgebung: ZavCloud M4 Mac mini Cloud — ideal vor dem Hardwarekauf.