
Je pensais que 16 Go + SSD externe suffisaient pour Ollama. Puis le Mac mini est devenu ma machine du quotidien — Chrome (~20 onglets), VS Code, Slack et qwen3:8b en permanence. En une semaine, la pression mémoire est passée au jaune, le swap autour de 1 Go. La collègue en 24 Go, même modèle, même script : barre verte.
Pas une fiche technique recyclée : sept jours face à face sur deux Mac mini M4 (16 / 24 Go), protocole et chiffres. Plus Qwen3, DeepSeek R1, Gemma 3 en 2026, et l’impact de OpenHuman, Claude Code ou MLX sur la RAM.
Semaine de test : même scène avec qwen3:8b
Matériel : Mac mini M4 (10 cœurs CPU / 10 GPU), une unité 16 Go et une 24 Go, macOS et logiciels alignés. Période : 26.05–01.06.2026, 2 h/jour « dev + chat », chaque métrique 3 mesures, médiane.
Environnement commun (bureau réel) :
- macOS 16 (canal bêta 26.x, même build)
- Ollama 0.12.3 (
ollama --version) - Google Chrome : 20 onglets (Notion, GitHub, Gmail)
- Visual Studio Code + packs de langue
- Slack desktop en arrière-plan
Inférence (lecture après 5 min de régime établi) :
ollama pull qwen3:8b ollama run qwen3:8b # Second terminal : prompts 512 tokens, lire Mémoire/Swap après 2 min de génération
Mac mini M4 16 Go
| Métrique | Valeur | Note |
|---|---|---|
| Mémoire utilisée | 13,2 Go | Moniteur d’activité → Mémoire |
| Swap | 1,1 Go | Pression jaune, ventilateur parfois |
| Génération | 34 tok/s | voir ollama run --verbose |
| Ressenti | Chrome saccadé au scroll | quand swap élevé |
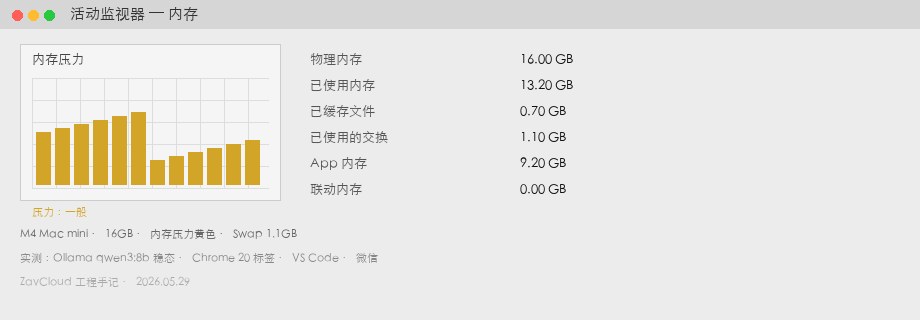
qwen3:8b stable + Chrome / VS Code / Slack. 13,2 Go, 1,1 Go swap, pression jaune.Mac mini M4 24 Go
| Métrique | Valeur | Note |
|---|---|---|
| Mémoire utilisée | 16,4 Go | même scène |
| Swap | 0 Go | pression verte |
| Génération | 37 tok/s | GPU proche ; écart surtout sans swap |
| Marge | ~7,6 Go | ex. nomic-embed ou second modèle 3B |
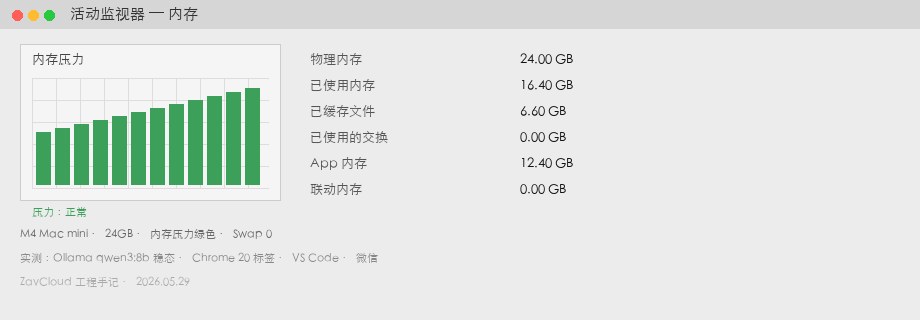
« Mauvaise config » signifie quoi ?
Pas que 16 Go interdit Ollama : ma charge n’est pas un benchmark isolé. API cloud + ollama run rare → 16 Go OK. Bureau type « navigateur + IDE + Qwen3/DeepSeek + agent » → 24 Go plus serein.
Comment nous avons mesuré (reproductible)
Tous les tableaux suivent ce flux — reproductible en une demi-journée :
- Poids —
ollama show qwen3:8b --modelfileet taille*.gguf. - RAM stable — après chargement : utilisé / swap / pression.
- tok/s — prompt 512 tokens,
--verbose, eval rate.
ollama run qwen3:8b --verbose \ "Explique la mémoire unifiée Apple en français (~400 mots), trois avantages et inconvénients." # moyenne de 3 eval rate (tokens/s) vm_stat | awk '/swap/ {print}' memory_pressure
Variables : version Ollama et quantification (Q4_K_M vs Q5) ±0,5–1,5 Go. Mesurer Gemma 3 / DeepSeek R1 après votre ollama pull.
Modèles courants sur Mac mini M4 (2026)
✅ confortable ; ⚠️ swap ou fermer des apps ; ❌ pas en modèle principal (avec la charge ci-dessus).
| Modèle (tag Ollama) | 16 Go | 24 Go | Semaine de test |
|---|---|---|---|
Qwen3 8B qwen3:8b |
✅ | ✅ | 16 Go : ~1,1 Go swap ; 24 Go : 0 |
DeepSeek R1 8B deepseek-r1:8b |
✅ | ✅ | ~5,2 Go poids ; courbe proche Qwen3 8B |
Qwen3 14B qwen3:14b |
⚠️ | ✅ | 16 Go : swap 2,3 Go+ |
| Gemma 3 27B (quantifié) | ❌ | ⚠️ | 24 Go essai seulement ; long contexte → OOM |
| Llama 3.2 3B | ✅ | ✅ | bon sidecar embed / RAG |
Avec MLX, ordre de grandeur proche, pics plus aigus avec compile + Xcode — observer 5 min en régime établi.
14B et DeepSeek (même bureau)
Seul le modèle Ollama change ; Chrome / VS Code / Slack inchangés :
| Modèle | RAM | Utilisé | Swap | tok/s |
|---|---|---|---|---|
deepseek-r1:8b |
16 Go | 13,5 Go | 1,0 Go | 33 |
deepseek-r1:8b |
24 Go | 16,6 Go | 0 | 36 |
qwen3:14b |
16 Go | 15,8 Go | 2,3 Go | 18 |
qwen3:14b |
24 Go | 19,1 Go | 0 | 28 |
En bref : Qwen3 / DeepSeek 14B au quotidien → 16 Go en lutte swap ; 24 Go garde navigateur et IDE sans mode « tout fermer ».
Pourquoi « 14B Q4 ~8–10 Go » — et la mesure
- GGUF disque —
ollama pull qwen3:14b≈ 8,4–9,2 Go. - Cache KV — contexte 8k souvent +1–3 Go ;
OLLAMA_CONTEXT_LENGTHgrand pousse vite le 16 Go. - Total mesuré —
qwen3:14ben 24 Go : 19,1 Go = modèle + KV + Chrome/IDE/système (~5–6 Go). Part modèle ~13–14 Go — cohérent avec « 8–10 Go poids + runtime ».
14B Q4 possible, pas avec le bureau plein — 24 Go, ou onglets/contexte réduits, embed sur une autre machine.
Claude Code, OpenHuman — RAM en plus
- Claude Code + Ollama — agent API, Ollama brouillon offline. VS Code/Cursor 1–2 Go + Chrome : 16 Go sans marge 14B.
- OpenHuman +
qwen3:8b— processus fond ~1 Go+ ; voir guide d’installation OpenHuman. En 24 Go : sync OAuth + 8B sans swap. - MLX — pics avec Xcode/Core ML ; batch sur nœud Core ML cloud dédié.
Gros dépôts CodeGraph + Claude Code MCP : on garde Chrome → pression vers 24 Go (CodeGraph local).
Quelle config acheter (mesures, pas la fiche Apple)
- 16 Go — 8B seulement (Qwen3 / DeepSeek R1), swap accepté, ou API cloud + Ollama secours.
- 24 Go — 14B + navigateur + IDE + agent, essais Gemma 3 27B, horizon 3–5 ans sans mur RAM sur le mini.
Le comparatif coût GPU cloud reste complémentaire : RAM = confort local ; cloud = 7×24 et IP fixe.
Mac mini M4 vs RTX 5060 — quelle voie pour l’IA locale ?
Beaucoup opposent mémoire unifiée Apple et VRAM NVIDIA (RTX 5060). ZavCloud propose des Cloud Mac (Mac mini M4 exclusifs) : pas « n’achetez pas de GPU », mais Mac vs RTX vs GPU cloud.
Mac Studio monte le plafond RAM (64 Go+). AWS / Alibaba GPU pour 70B, entraînement, lots SD. Tableaux avec la même hypothèse Chrome+IDE.
Où le Mac mini M4 gagne
| Scénario | Mac mini M4 | Commentaire |
|---|---|---|
| Dev iOS / macOS | ✅ | Xcode, TestFlight — un PC RTX ne remplace pas |
| Claude Code / Cursor | ✅ | agent terminal + brouillon Ollama ; moins d’OOM VRAM |
| IA locale (texte 8B–14B) | ✅ | Qwen3 / DeepSeek 8B–14B ; 24 Go sans swap |
| OpenHuman / MLX / Core ML | ✅ | stack Apple ; Core ML cloud |
| Jeux AAA / entraînement CUDA | ❌ | hors cible du Mac mini |
Où un PC RTX 5060 gagne
| Scénario | RTX 5060 | Commentaire |
|---|---|---|
| Jeux PC | ✅ | Windows + GPU dédiée |
| Stable Diffusion / ComfyUI | ✅ | écosystème CUDA ; Mac en retrait |
| 70B quantifié | ✅ | 12 Go VRAM + RAM système ; 24 Go Mac mini ⚠️ pour 27B |
| Multi-GPU / entraînement | ✅ | 5070 Ti, dual, ou GPU cloud ; pas de CUDA sur Mac |
| Publication App Store | ❌ | Mac requis — souvent « RTX render + Cloud Mac package » |
Hybride (fréquent chez nos clients)
Mac local ou Cloud (24 Go) pour Ollama / Claude Code / iOS ; RTX ou GPU cloud pour SD et 70B. Swap critique en 16 Go : tester le 14B une semaine sur Cloud Mac 24 Go. Facturation : M4 vs GPU cloud.
Avant d’acheter : mesurer une semaine
- Lister ce que vous ne fermez pas (onglets, IDE, messagerie, agent) ;
- Qwen3 8B + 14B 30 min chacun, noter swap et tok/s ;
- 14B swap > 1 Go en continu → écarter 16 Go.
Sans machine : louer un Cloud Mac Apple Silicon identique, faire tourner Ollama/agents une semaine, puis acheter.
Schéma courant : 16 Go en local + 24 Go cloud pour Ollama/OpenHuman. ZavCloud : Mac mini M4 exclusifs (macOS, IP fixe) pour essai avant achat. Tarifs location Mac mini.
- À lire aussi — M4 vs GPU cloud · OpenHuman × Ollama · Claude Code + CodeGraph
FAQ
Douze questions fréquentes — alignées sur les tableaux ci-dessus.
Combien de RAM pour Qwen3 14B ?
Même charge bureau : qwen3:14b ~19,1 Go (24 Go) ; 16 Go : 15,8 Go + 2,3 Go swap. Poids GGUF 8,4–9,2 Go + KV — 24 Go conseillés.
DeepSeek R1 14B ?
deepseek-r1:8b en 16 Go comme Qwen3 8B. 14B comme qwen3:14b : 24 Go sans swap, 16 Go ~18 tok/s. 14B principal → 24 Go.
16 Go est-il obsolète ?
Pas du jour au lendemain. Norme 2026 : navigateur + IDE + 8B + agent. 16 Go pour 8B, API-first, fermer des onglets.
Durée de vie des 24 Go ?
3–5 ans sweet spot pour 8B–14B + agent desktop. 32B+ → Mac Studio / GPU cloud (RAM non extensible sur mini).
Ollama ou MLX ?
Chat : Ollama. MLX pics avec Xcode — batch sur nœud dédié.
Mac mini ou RTX 5060 ?
Texte 8B–14B, Claude Code, iOS : Mac mini M4 (24 Go). SD, 70B, jeux : RTX 5060. Souvent les deux.
16 Go pour Qwen3 8B ?
Oui : 13,2 Go, ~1,1 Go swap, 34 tok/s. Zéro swap : 24 Go.
24 Go plus rapide ?
qwen3:8b ~9 % (34 vs 37). Valeur : pas de swap, 14B + petit modèle.
Gemma 3 27B en 24 Go ?
⚠️ essai quantifié ; long contexte → OOM. 8B–14B zone confort.
Mac Studio pour l’IA ?
8B–14B + dev : Mac mini M4 24 Go. 64 Go ou plusieurs gros modèles → Studio ou Cloud Mac d’abord.
Indécis sur la RAM ?
Mesurer 8B + 14B. Sans Mac : Cloud Mac M4 24 Go une semaine.
Reproductible ?
Oui. Ollama 0.12.x, ±10 % ; tendance 16 Go swap / 24 Go zéro / 14B → 24 Go.
Retour d’expérience
RAM incertaine ? Mesurez une semaine
Même charge (Chrome, IDE, qwen3:8b / qwen3:14b), swap et pression mémoire. Pour un macOS exclusif proche de la prod : Cloud Mac mini M4 ZavCloud — idéal avant l’achat matériel.