
当初は 16GB + 外付け SSD で Ollama を回せば十分だと思っていました。ところが日常のメイン機にして——Chrome タブ20前後、VS Code、Slack に加え qwen3:8b を常駐させると——1週間も経たず Activity Monitor のメモリ圧力が黄色に。Swap は常に 1GB 前後。同じモデル・同じスクリプトの 24GB 機は、圧力バーが緑のままです。
スペック表の転載ではなく、M4 Mac mini(16GB / 24GB)2台を7日間並走した記録です。何を測り、どう測り、数字の出所はどこかを書きます。Qwen3、DeepSeek R1、Gemma 3 を 2026 年にどう選ぶか、OpenHuman、Claude Code、MLX と重ねたときメモリがどう溢れるかも整理します。
1週間実測:同シナリオで qwen3:8b
テスト機:Mac mini M4(10 コア CPU / 10 コア GPU)、16GB 1台・24GB 1台。OS とアプリのバージョンは揃えています。期間:2026.05.26–06.01。毎日2時間の「開発 + チャット」混合負荷。各指標は3回連続計測の中央値。
共通環境(裸の単一タスクではなく、実デスクトップに近づけた):
- macOS 16(26.x テストチャネル、同一 build)
- Ollama 0.12.3(
ollama --version) - Google Chrome:20 タブ(Notion、GitHub、Gmail など)
- Visual Studio Code + 日本語 Language Pack
- Slack デスクトップ常駐
推論コマンド(定常5分後に読み取り):
ollama pull qwen3:8b ollama run qwen3:8b # 別ターミナル:512 token プロンプトを連続投入し、2分後の Memory / Swap を記録
M4 Mac mini 16GB 実測
| 項目 | 数値 | 備考 |
|---|---|---|
| メモリ使用(Memory Used) | 13.2 GB | Activity Monitor → メモリ →「使用中」 |
| Swap Used | 1.1 GB | メモリ圧力黄色、ファンが時々上がる |
| 生成速度 | 34 tok/s | 下記 ollama run --verbose 手順 |
| 体感 | Chrome への切り替えでスクロールが重い | Swap が高いときに発生、常時ではない |
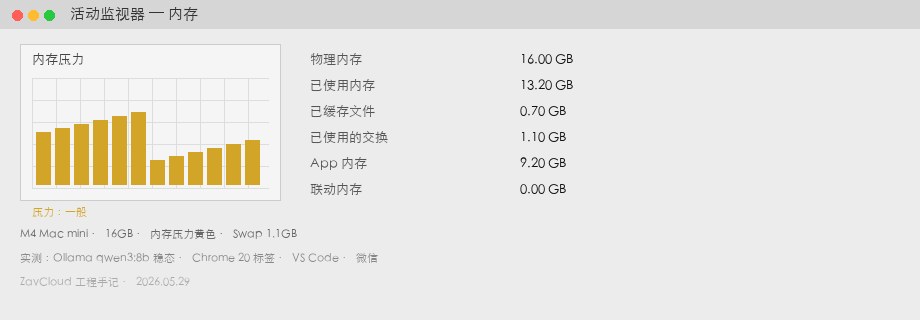
qwen3:8b 定常 + Chrome / VS Code / Slack)。使用 13.2GB、Swap 1.1GB、圧力黄色。M4 Mac mini 24GB 実測
| 項目 | 数値 | 備考 |
|---|---|---|
| メモリ使用 | 16.4 GB | 同シナリオ・同モデル |
| Swap Used | 0 GB | メモリ圧力緑 |
| 生成速度 | 37 tok/s | モデル算力は近く、差は主に Swap の有無 |
| 余裕 | 約 7.6 GB | nomic-embed や 3B サイドカーを追加可能 |
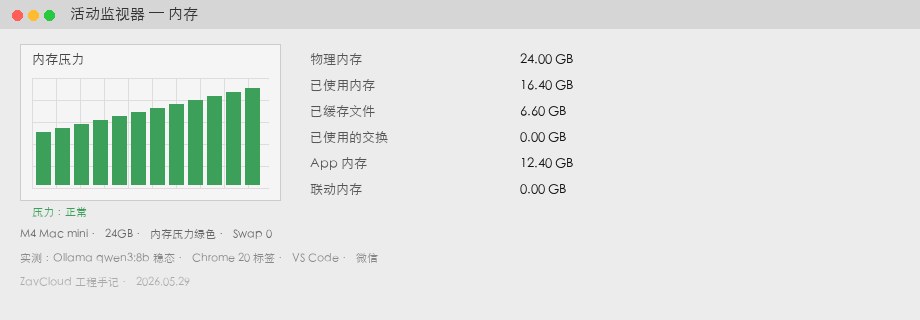
「買い違え」とは?
16GB で Ollama が動かないわけではありません。自分の負荷が実験室の単一タスクではなかったということです。API 中継とたまの ollama run なら 16GB も妥当。デフォルトが「ブラウザ + IDE + ローカル Qwen3/DeepSeek + Agent」なら 24GB が保険になります。
計測方法(再現可能)
本文の表の数字はすべて次の手順で取得しています。同じ Mac なら半日程度で再現できます:
- 重みサイズ —
ollama show qwen3:8b --modelfileとモデルディレクトリの*.ggufファイルサイズ(ディスク ≠ 常駐メモリだが下限になる)。 - 常駐メモリ — モデルロード後、Activity Monitor の「メモリ」で Memory Used / Swap Used / Memory Pressure(黄/緑)を記録。
- 生成速度 — 512 token 固定プロンプトで
--verboseから eval rate を読む:
ollama run qwen3:8b --verbose \ "Apple 統合メモリについて400字で説明し、メリット・デメリットを3点ずつ列挙してください。" # 出力の eval rate(tokens/s)を3回平均 vm_stat | awk '/swap/ {print}' memory_pressure
含めていない要因:Ollama バージョン、量子化タグ(Q4_K_M vs Q5)で 0.5–1.5GB ずれることがあります。Gemma 3、DeepSeek R1 はタグを変えたら ollama pull 後に自前で再計測してください。下記 14B 行も同じ手順で追加計測しています。
2026 主流モデルの M4 Mac mini 占有(対照表)
記号:✅ 日常マルチタスクで常駐可;⚠️ 動くが Swap しやすい / アプリ整理が必要;❌ 主力非推奨。上記 Chrome+IDE 負荷前提(裸機ではない)。
| モデル(Ollama タグ例) | 16GB | 24GB | 1週間実測メモ |
|---|---|---|---|
Qwen3 8B qwen3:8b |
✅ | ✅ | 16GB:Swap 約 1.1GB;24GB:Swap ゼロ |
DeepSeek R1 8B deepseek-r1:8b |
✅ | ✅ | 重み約 5.2GB;曲線は Qwen3 8B に近い |
Qwen3 14B qwen3:14b |
⚠️ | ✅ | 16GB:Swap 2.3GB 以上(下記参照) |
| Gemma 3 27B(量子化版) | ❌ | ⚠️ | 24GB でも試用程度;コンテキストを伸ばすと OOM |
| Llama 3.2 3B | ✅ | ✅ | 埋め込み / RAG サイドカー向き |
MLX で同系の重みを回す場合、占有の形は Ollama に近いですがピークが「尖る」傾向があります。モデルカードのパラメータ数だけでなく、Activity Monitor で5分の定常を見てください。
追加実測:14B と DeepSeek(同環境)
Chrome / VS Code / Slack はそのまま、Ollama モデルのみ差し替え:
| モデル | 構成 | メモリ使用 | Swap | tok/s |
|---|---|---|---|---|
deepseek-r1:8b |
16GB | 13.5 GB | 1.0 GB | 33 |
deepseek-r1:8b |
24GB | 16.6 GB | 0 | 36 |
qwen3:14b |
16GB | 15.8 GB | 2.3 GB | 18 |
qwen3:14b |
24GB | 19.1 GB | 0 | 28 |
結論は明快:Qwen3 / DeepSeek 14B を日常主力にするなら、16GB は Swap と格闘し続けます。24GB ならブラウザと IDE を閉じずに済みます。
理論値 vs 実測:「14B Q4 約 8–10GB」の根拠
結論だけ「8–10GB」と書くと AI まとめに見えがちです。ここでは内訳を示し、上表 qwen3:14b と突き合わせます:
- 重みファイル —
ollama pull qwen3:14b後、ローカル GGUF は約 8.4–9.2GB(量子化タグで変動)。ディスク占有で、ロード後の常駐は mmap によりやや小さくなることもあるが、桁は変わらない。 - KV キャッシュ — コンテキスト 8k、batch=1 で 1–3GB 追加が一般的。
OLLAMA_CONTEXT_LENGTHを伸ばすと 16GB 機はより早く上限に触れる。 - 実測合計 — 同シナリオ
qwen3:14bの 24GB 機使用 19.1GB = 重み級 + KV + Chrome/IDE/システム(約 5–6GB)。モデル単体は 13–14GB 程度と逆算でき、「8–10GB 重み + 数 GB ランタイム」と整合。
つまり:14B Q4 自体は動くが、「フル装備デスクトップ」とはデフォルト共存しない——24GB に上げるか、タブを閉じ context を下げるか、RAG 埋め込みを別マシンへ。
Claude Code、OpenHuman と重ねたとき:メモリはさらに足りない
1週間のうち、2026 年に多い「開発 + ローカルモデル」の組み合わせも試しました:
- Claude Code + ローカル Ollama — ターミナル Agent は Anthropic API、Ollama はオフライン下書きや機密断片用。VS Code / Cursor だけで 1–2GB、Chrome 加算で 16GB 機に 14B の余裕はほぼない。
- OpenHuman +
qwen3:8b— デスクトップ Agent と Memory Tree 同期でバックグラウンドが安定して 1GB+。手順はOpenHuman インストールガイド参照。24GB 機なら OAuth 同期 + 8B を Swap なしで維持可能。 - MLX — Xcode / Core ML パイプラインと同時だとコンパイルピークで一瞬メモリ上限。専有 macOS ノードでバッチ処理し、16GB 開発機と役割分担が現実的。
大規模リポジトリに CodeGraph + Claude Code MCP を足すと、索引自体はメモリを食い尽くしませんが、Chrome を閉じたくなくなる——結果的に 24GB 側へ押されます(CodeGraph ローカル構築参照)。
購入結論(実測ベース、スペック表ではない)
- 16GB を選ぶ — ローカルは 8B 級(Qwen3 / DeepSeek R1)中心、Swap とたまのタブ整理は許容;または Claude / GPT API が主力で Ollama は予備。
- 24GB を選ぶ — デフォルトが 14B + ブラウザ + IDE + Agent;Gemma 3 27B を試す余白が欲しい;3–5 年メモリで詰まりたくない。
GPU クラウドとのコスト比較と矛盾しません。メモリ容量は「1台で快適か」、クラウドは「24/7 と固定 IP」の話です。
M4 Mac mini と RTX 5060 自作、どちらを買う?
「ローカル AI」で実際に比較されているのは、Apple Silicon 統合メモリ(Mac mini / Mac Studio) と NVIDIA VRAM(RTX 5060 構成) の2ルートです。ZavCloud は Cloud Mac——専有 macOS の M4 Mac mini——を提供しているので「GPU を買うな」とは言いません。境界をはっきりさせます:どの用途が Mac に、どれが RTX かクラウド GPU に向くか。
Mac Studio はメモリ上限を 64GB+ に上げるだけで、シーンは Apple エコシステム寄り。AWS / 阿里云 GPU は 70B フル、学習、Stable Diffusion バッチ向き。以下は「実デスクトップ負荷」(Chrome + IDE 前提)の整理です。
M4 Mac mini が有利なシーン
| シーン | M4 Mac mini | 補足 |
|---|---|---|
| iOS / macOS 開発 | ✅ | Xcode、TestFlight、実機デバッグ;RTX では代替不可 |
| Claude Code / Cursor | ✅ | ターミナル Agent + ローカル Ollama 下書き;統合メモリで VRAM OOM が少ない |
| ローカル AI(8B–14B テキスト) | ✅ | Qwen3 / DeepSeek R1 8B–14B;24GB なら Swap ゼロ常駐 |
| OpenHuman / MLX / Core ML | ✅ | Apple スタック推論と端末デプロイ;Core ML クラウドノード |
| 3A ゲーム / CUDA 学習 | ❌ | Mac mini の設計目的外 |
RTX 5060 自作が有利なシーン
| シーン | RTX 5060 構成 | 補足 |
|---|---|---|
| PC ゲーム | ✅ | 独顕と Windows エコシステム;Mac mini では厳しい |
| Stable Diffusion / ComfyUI | ✅ | CUDA プラグインとコミュニティモデルが最充実;Mac も可だが一段弱い |
| 70B 級大モデル(量子化) | ✅ | 12GB VRAM + システム RAM で積み上げ;24GB Mac mini は 27B 試用 ⚠️ 程度 |
| マルチ GPU / 学習 | ✅ | 5070 Ti 換装、デュアル、またはクラウド GPU;Mac に CUDA はない |
| App Store 申請 | ❌ | 結局 Mac が必要;「RTX で生成 + Cloud Mac で署名」がよくある組み合わせ |
ハイブリッド(当社顧客で最多)
ローカル or Cloud Mac(24GB) で Ollama / Claude Code / iOS;RTX かクラウド GPU で SD と 70B。16GB Mac mini で Swap が限界なら、まず 14B を24GB Cloud Macへ移して1週間圧測し、RTX 追加要否を判断。課金モデルはM4 推論 vs GPU クラウド参照。
購入前:1週間試してから決める
16GB と 24GB で迷うなら、次の順が安全です:
- 閉じないアプリを書き出す(タブ数、IDE、Slack、Agent);
- 上記コマンドで Qwen3 8B + 14B を各30分、Swap と tok/s を記録;
- 14B で Swap が常時 1GB 超なら 16GB は除外。
実機がなければ、同構成 Apple Silicon クラウドで Ollama ワークフロー・ナレッジベース・Agent を1週間走らせ、メモリ曲線を見てから实体を買う方が、盲目的な構成アップより安上がりなことが多いです。
Mac mini クラウド運用では「手元 16GB で開発 + クラウド 24GB で Ollama / OpenHuman 常駐」が定番です——ZavCloud の M4 Mac mini 専有インスタンス(ネイティブ macOS、固定 IP)は購入前の圧測向きで、判断の代行ではありません。詳細はMac mini クラウドレンタルをご覧ください。
よくある質問(FAQ)
検索で多い質問を、上記実測表と揃えて整理しました。再現時の参照用です。
Qwen3 14B にはどれくらいメモリが必要?
本文と同じデスクトップ負荷(Chrome 約20タブ、VS Code、Slack)で、qwen3:14b 定常時使用約 19.1GB(24GB 機)。16GB 機は 15.8GB 使用 + 2.3GB Swap。モデル本体だけなら GGUF 重み 8.4–9.2GB に KV とシステム分が加わり、実用下限は 24GB 統合メモリ。16GB はブラウザを閉じ OLLAMA_CONTEXT_LENGTH を下げる実験向き。
DeepSeek R1 14B は動く?
deepseek-r1:8b は 16GB で常駐可(Swap 約 1GB、33 tok/s)、Qwen3 8B と同級。14B 級(deepseek-r1:14b 等)は qwen3:14b に近い曲線:24GB なら Swap ゼロ(約 28 tok/s 級)、16GB は長期 Swap で約 18 tok/s。14B 主力なら 24GB、16GB への賭けは非推奨。
16GB はもう時代遅れ?
一夜にして淘汰されないが、2026 年のデフォルト負荷は「たまの ollama run」から「ブラウザ + IDE + 8B 常駐 + Agent」へ移っています。16GB が向くのは 8B 推論、API 中心、タブ整理 OK。Claude Code / OpenHuman をデフォルト ON にしたく Swap も避けたいなら、16GB は「入門」に近づいています。
24GB は何年持つ?
現行ペース(8B–14B 主力、27B 試用)なら 24GB は約 3–5 年「デスクトップ + ローカル Agent」のスイートスポット:14B、埋め込み、開発ツールを同時に載せられる。それ以上(32B+ 常駐)は Mac Studio / クラウド GPU を計画。Mac mini は出荷後メモリ増設不可。
Ollama と MLX、どちらがメモリに優しい?
日常対話推論:Ollama が扱いやすい。 GGUF + 常駐プロセスの footprint が予測しやすく、Activity Monitor の読みと一致。MLX はロード・コンパイル、Xcode パイプライン同時実行でピークが尖る。平均が低くても一瞬で上限に触れ Swap しやすい。Ollama をデフォルトチャット/RAG に、MLX はバッチか専有ノードへ。
Mac mini と RTX 5060、ローカル AI 向きはどちら?
テキスト 8B–14B、Claude Code、iOS 開発:M4 Mac mini(24GB 推奨)。 統合メモリ + macOS ツールチェーンが強み。Stable Diffusion、70B 量子化、ゲーム:RTX 5060。 VRAM と CUDA エコシステムは Mac mini では代替不可。最終形は「Mac mini + RTX かクラウド GPU」の分担が多いです。
M4 Mac mini 16GB で Qwen3 8B は足りる?
足ります。実測 13.2GB 使用、Swap 約 1.1GB、34 tok/s、メモリ圧力黄色。たまのカクつき OK なら 16GB;Swap ゼロのデスクトップなら 24GB(16.4GB 使用、37 tok/s)。
24GB は 16GB より Ollama がどれだけ速い?
同モデル qwen3:8b で約 9%(34 vs 37 tok/s)のみ。24GB の核心はSwap ゼロ、14B と第2小モデルの余裕で、生算力2倍ではありません。
Gemma 3 27B は 24GB Mac mini で動く?
⚠️ 強量化での試用のみ;コンテキストを伸ばすと OOM。8B–14B が 24GB の快適域。27B 主力は RTX かクラウド GPU。
AI のために Mac Studio に課金する価値は?
8B–14B + 開発だけなら M4 Mac mini 24GB のコスパが高い。64GB 統合メモリ、複数 14B/32B、重い MLX パイプラインが必要なら Mac Studio;まず Cloud Mac でメモリ曲線を検証してから Studio 判断も合理的。
どのメモリ容量を買うか迷ったら?
本文コマンドで 8B + 14B を各30分、Swap とメモリ圧力を確認。実機がなければ同構成 M4 Mac mini クラウド(24GB)に Ollama / OpenHuman を載せ1週間観察——盲目の増配や RTX 先行より安いことが多い。
実測データは再現できる?
できます。Ollama 0.12.x、同じ Chrome/IDE/Slack シナリオなら絶対値は ±10% 程度のブレがありますが、16GB で Swap、24GB で Swap ゼロ、14B は 24GB という傾向は一致するはずです。
経験談
メモリ容量に迷う? 先に1週間回してから決めよう
本文と同じ負荷(Chrome、IDE、qwen3:8b / qwen3:14b)で Swap とメモリ圧力を記録。本番同等の専有 macOS 環境で対照したい場合、ZavCloud の M4 Mac mini クラウドが購入前検証に向きます。