
처음엔 16GB + 외장 SSD면 Ollama 돌리기에 충분하다고 봤습니다. 그런데 일상 메인 머신으로 쓰니——Chrome 탭 20개 안팎, VS Code, Slack에 qwen3:8b까지 상시 구동——일주일도 안 돼 Activity Monitor 메모리 압력이 노란색으로 바뀌었고, Swap은 1GB 전후로 떠 있습니다. 같은 모델·같은 스크립트의 24GB 기는 압력 바가 계속 초록입니다.
스펙표 베끼기가 아니라 M4 Mac mini(16GB / 24GB) 두 대를 7일간 병행한 기록입니다. 무엇을, 어떻게 쟀는지, 숫자 출처까지 적습니다. Qwen3, DeepSeek R1, Gemma 3를 2026년에 어떻게 고를지, OpenHuman, Claude Code, MLX와 겹칠 때 메모리가 어떻게 터지는지도 정리합니다.
1주 실측: 같은 시나리오로 qwen3:8b
테스트 기: Mac mini M4(10코어 CPU / 10코어 GPU), 16GB 1대·24GB 1대. OS와 앱 버전은 맞춤.기간: 2026.05.26–06.01. 매일 2시간 「개발 + 채팅」 혼합 부하. 각 지표는 3회 연속 측정 중앙값.
공통 환경(랩 단일 태스크가 아니라 실제 데스크톱에 가깝게):
- macOS 16(26.x 테스트 채널, 동일 build)
- Ollama 0.12.3(
ollama --version) - Google Chrome: 20탭(Notion, GitHub, Gmail 등)
- Visual Studio Code + 한국어 Language Pack
- Slack 데스크톱 상시 실행
추론 명령(정상 5분 후 읽기):
ollama pull qwen3:8b ollama run qwen3:8b # 별도 터미널: 512 token 프롬프트 연속 입력, 2분 후 Memory / Swap 기록
M4 Mac mini 16GB 실측
| 항목 | 수치 | 비고 |
|---|---|---|
| 메모리 사용(Memory Used) | 13.2 GB | Activity Monitor → 메모리 →「사용됨」 |
| Swap Used | 1.1 GB | 메모리 압력 노란색, 팬이 가끔 올라감 |
| 생성 속도 | 34 tok/s | 아래 ollama run --verbose 방법 |
| 체감 | Chrome 전환 시 스크롤 끈적 | Swap 높을 때 발생, 상시는 아님 |
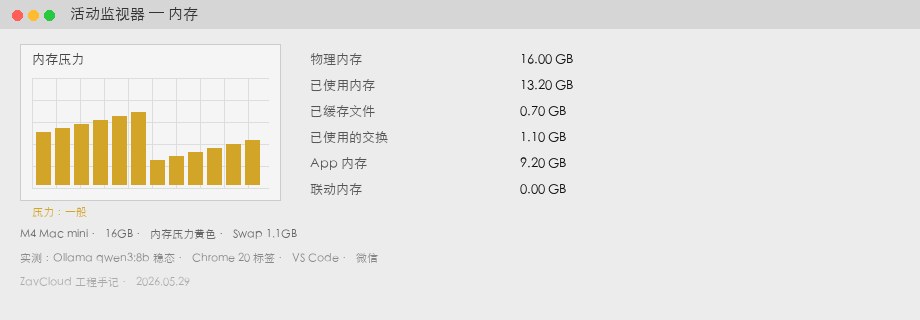
qwen3:8b 정상 + Chrome / VS Code / Slack). 사용 13.2GB, Swap 1.1GB, 압력 노란색.M4 Mac mini 24GB 실측
| 항목 | 수치 | 비고 |
|---|---|---|
| 메모리 사용 | 16.4 GB | 동일 시나리오·동일 모델 |
| Swap Used | 0 GB | 메모리 압력 초록 |
| 생성 속도 | 37 tok/s | 모델 연산력은 비슷, 차이는 주로 Swap 유무 |
| 여유 | 약 7.6 GB | nomic-embed 또는 3B 사이드카 추가 가능 |
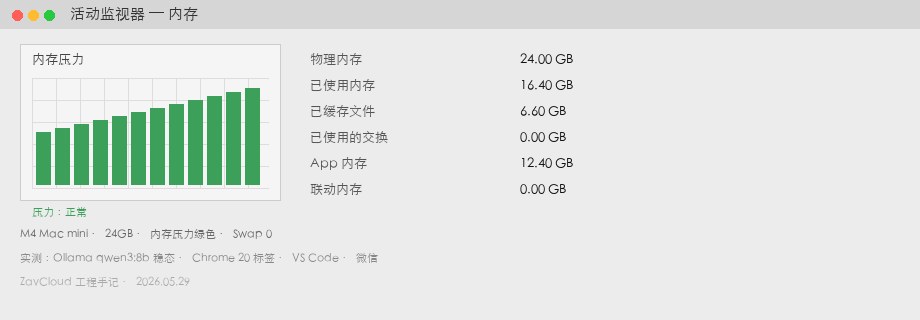
「잘못 샀다」는 무슨 뜻?
16GB에서 Ollama가 안 돌아가는 게 아닙니다. 제 부하는 실험실 단일 태스크가 아니었다는 뜻입니다. API 중계와 가끔의 ollama run이면 16GB도 타당합니다. 기본이 「브라우저 + IDE + 로컬 Qwen3/DeepSeek + Agent」면 24GB가 보험입니다.
측정 방법(재현 가능)
본문 표의 숫자는 모두 아래 절차로 수집했습니다. 같은 Mac이면 반나절 안에 재현 가능합니다:
- 가중치 크기 —
ollama show qwen3:8b --modelfile과 모델 디렉터리*.gguf파일 크기(디스크 ≠ 상시 메모리지만 하한). - 상시 메모리 — 모델 로드 후 Activity Monitor 「메모리」에서 Memory Used / Swap Used / Memory Pressure(노랑/초록) 기록.
- 생성 속도 — 512 token 고정 프롬프트로
--verbose에서 eval rate 읽기:
ollama run qwen3:8b --verbose \ "Apple 통합 메모리에 대해 400자로 설명하고, 장단점을 각 3가지씩 나열해 주세요." # 출력 eval rate(tokens/s) 3회 평균 vm_stat | awk '/swap/ {print}' memory_pressure
넣지 않은 요인: Ollama 버전, 양자화 태그(Q4_K_M vs Q5)에 따라 0.5–1.5GB 흔들릴 수 있습니다. Gemma 3, DeepSeek R1은 태그 바꾸면 ollama pull 후 직접 재측정하세요. 아래 14B 행도 같은 방법으로 추가 측정했습니다.
2026 주류 모델 M4 Mac mini 점유(대조표)
기호: ✅ 일상 멀티태스킹 상시 구동; ⚠️ 돌아가나 Swap/앱 정리 필요; ❌ 메인 비추천. 위 Chrome+IDE 부하 전제(베어 메탈 아님).
| 모델(Ollama 태그 예) | 16GB | 24GB | 1주 실측 메모 |
|---|---|---|---|
Qwen3 8B qwen3:8b |
✅ | ✅ | 16GB: Swap 약 1.1GB; 24GB: Swap 0 |
DeepSeek R1 8B deepseek-r1:8b |
✅ | ✅ | 가중치 약 5.2GB; 곡선 Qwen3 8B와 유사 |
Qwen3 14B qwen3:14b |
⚠️ | ✅ | 16GB: Swap 2.3GB+(아래 참조) |
| Gemma 3 27B(양자화) | ❌ | ⚠️ | 24GB도 시험용; 컨텍스트 늘리면 OOM |
| Llama 3.2 3B | ✅ | ✅ | 임베딩/RAG 사이드카에 적합 |
MLX로 같은 계열 가중치를 돌리면 형태는 Ollama와 비슷하지만 피크가 「날카롭습니다」. 모델 카드 파라미터만 보지 말고 Activity Monitor로 5분 정상을 보세요.
추가 실측: 14B와 DeepSeek(동일 환경)
Chrome / VS Code / Slack은 그대로, Ollama 모델만 교체:
| 모델 | 구성 | 메모리 사용 | Swap | tok/s |
|---|---|---|---|---|
deepseek-r1:8b |
16GB | 13.5 GB | 1.0 GB | 33 |
deepseek-r1:8b |
24GB | 16.6 GB | 0 | 36 |
qwen3:14b |
16GB | 15.8 GB | 2.3 GB | 18 |
qwen3:14b |
24GB | 19.1 GB | 0 | 28 |
결론은 분명합니다: Qwen3 / DeepSeek 14B를 일상 메인으로 쓰려면 16GB는 Swap과 계속 싸웁니다. 24GB면 브라우저와 IDE를 닫지 않아도 됩니다.
이론값 vs 실측: 「14B Q4 약 8–10GB」 근거
결론만 「8–10GB」라 쓰면 AI 요약 같습니다. 여기서는 내역을 보이고 위 표 qwen3:14b와 맞춥니다:
- 가중치 파일 —
ollama pull qwen3:14b후 로컬 GGUF 약 8.4–9.2GB(양자화 태그에 따라). 디스크 점유, 로드 후 상시는 mmap으로 약간 작을 수 있으나 자릿수는 같음. - KV 캐시 — 컨텍스트 8k, batch=1에서 1–3GB 추가가 흔함.
OLLAMA_CONTEXT_LENGTH를 늘리면 16GB 기가 더 빨리 한계. - 실측 합계 — 동일 시나리오
qwen3:14b24GB 기 사용 19.1GB = 가중치급 + KV + Chrome/IDE/시스템(약 5–6GB). 모델만 역산하면 13–14GB, 「8–10GB 가중치 + 수 GB 런타임」과 일치.
즉: 14B Q4 자체는 돌지만 「풀옵션 데스크톱」과 기본 공존은 어렵다——24GB로 올리거나, 탭을 닫고 context를 내리거나, RAG 임베딩을 다른 머신으로.
Claude Code, OpenHuman 겹칠 때: 메모리는 더 부족
1주 중 2026년 흔한 「개발 + 로컬 모델」 조합도 시험했습니다:
- Claude Code + 로컬 Ollama — 터미널 Agent는 Anthropic API, Ollama는 오프라인 초안·민감 구간용. VS Code / Cursor만 1–2GB, Chrome 더하면 16GB 기에 14B 여유는 거의 없음.
- OpenHuman +
qwen3:8b— 데스크톱 Agent와 Memory Tree 동기화로 백그라운드가 안정적으로 1GB+. 방법은 OpenHuman 설치 가이드 참조. 24GB 기면 OAuth 동기 + 8B를 Swap 없이 유지 가능. - MLX — Xcode / Core ML 파이프라인과 동시면 컴파일 피크가 순간 상한. 전용 macOS 노드에서 배치하고 16GB 개발기와 역할 분담이 현실적.
대형 저장소에 CodeGraph + Claude Code MCP를 더하면 인덱스 자체는 메모리를 다 먹진 않지만 Chrome을 닫기 싫어집니다——결국 24GB 쪽으로 밀립니다(CodeGraph 로컬 구축 참조).
구매 결론(실측 기준, 스펙표 아님)
- 16GB 선택 — 로컬은 8B급(Qwen3 / DeepSeek R1) 중심, Swap·가끔 탭 정리 OK; 또는 Claude / GPT API가 메인이고 Ollama는 예비.
- 24GB 선택 — 기본이 14B + 브라우저 + IDE + Agent; Gemma 3 27B 시험 여유; 3–5년 메모리로 막히고 싶지 않음.
GPU 클라우드 비용 비교와 모순되지 않습니다. 메모리 용량은 「한 대에서 편한가」, 클라우드는 「24/7과 고정 IP」 이야기입니다.
M4 Mac mini vs RTX 5060 조립 PC, 뭘 살까?
「로컬 AI」 검색의 실제 비교는 Apple Silicon 통합 메모리(Mac mini / Mac Studio)와 NVIDIA VRAM(RTX 5060 구성) 두 갈래입니다. ZavCloud는 Cloud Mac——전용 macOS M4 Mac mini——를 제공하므로 「GPU 사지 마」가 아닙니다. 경계를 분명히 합니다: 어떤 용도가 Mac에, 어떤 게 RTX나 클라우드 GPU에 맞는지.
Mac Studio는 메모리 상한만 64GB+로 올리고, 장면은 Apple 생태계 쪽.AWS / 알리바바 GPU는 70B 풀, 학습, Stable Diffusion 배치용. 아래는 「실제 데스크톱 부하」(Chrome + IDE 전제) 정리입니다.
M4 Mac mini가 유리한 장면
| 장면 | M4 Mac mini | 설명 |
|---|---|---|
| iOS / macOS 개발 | ✅ | Xcode, TestFlight, 실기기 디버깅; RTX로 대체 불가 |
| Claude Code / Cursor | ✅ | 터미널 Agent + 로컬 Ollama 초안; 통합 메모리로 VRAM OOM 적음 |
| 로컬 AI(8B–14B 텍스트) | ✅ | Qwen3 / DeepSeek R1 8B–14B; 24GB면 Swap 0 상시 |
| OpenHuman / MLX / Core ML | ✅ | Apple 스택 추론·엣지 배포; Core ML 클라우드 노드 |
| 3A 게임 / CUDA 학습 | ❌ | Mac mini 설계 목적 밖 |
RTX 5060 조립 PC가 유리한 장면
| 장면 | RTX 5060 구성 | 설명 |
|---|---|---|
| PC 게임 | ✅ | 독립 GPU와 Windows 생태; Mac mini에선 어려움 |
| Stable Diffusion / ComfyUI | ✅ | CUDA 플러그인·커뮤니티 모델 최다; Mac도 가능하나 한 단계 약함 |
| 70B급 대형 모델(양자화) | ✅ | 12GB VRAM + 시스템 RAM 적층; 24GB Mac mini는 27B 시험 ⚠️ 수준 |
| 멀티 GPU / 학습 | ✅ | 5070 Ti 교체, 듀얼, 또는 클라우드 GPU; Mac엔 CUDA 없음 |
| App Store 제출 | ❌ | 결국 Mac 필요; 「RTX 생성 + Cloud Mac 서명」 조합 흔함 |
하이브리드(고객 중 최다)
로컬 또는 Cloud Mac(24GB)에서 Ollama / Claude Code / iOS; RTX 또는 클라우드 GPU에서 SD와 70B. 16GB Mac mini Swap 한계면 먼저 14B를 24GB Cloud Mac으로 옮겨 일주일 압측 후 RTX 추가 여부 판단. 과금 모델은 M4 추론 vs GPU 클라우드 참조.
구매 전: 일주일 돌려보고 결정
16GB vs 24GB가 헷갈리면 다음 순서가 안전합니다:
- 끄지 않을 앱 목록(탭 수, IDE, Slack, Agent);
- 위 명령으로 Qwen3 8B + 14B 각 30분, Swap과 tok/s 기록;
- 14B에서 Swap이 상시 1GB 넘으면 16GB 제외.
실기가 없으면 동일 Apple Silicon 클라우드에서 Ollama 워크플로·지식베이스·Agent를 일주일 돌려 메모리 곡선을 본 뒤 실물 구매——맹목적 스펙 업보다 저렴한 경우가 많습니다.
Mac mini 클라우드 운영에선 「손 16GB 개발 + 클라우드 24GB Ollama / OpenHuman 상시」가 정석입니다——ZavCloud M4 Mac mini 전용 인스턴스(네이티브 macOS, 고정 IP)는 구매 전 압측용이지, 판단 대행이 아닙니다. 자세한 내용은 Mac mini 클라우드 임대를 보세요.
자주 묻는 질문(FAQ)
검색 빈도 높은 질문을 위 실측표와 맞춰 정리했습니다. 재현 시 참고용입니다.
Qwen3 14B에는 메모리가 얼마나 필요한가요?
본문과 같은 데스크톱 부하(Chrome 약 20탭, VS Code, Slack)에서 qwen3:14b 정상 시 사용 약 19.1GB(24GB 기). 16GB 기는 15.8GB 사용 + 2.3GB Swap. 모델만 보면 GGUF 가중치 8.4–9.2GB에 KV·시스템 분량이 더해져 실용 하한은 24GB 통합 메모리. 16GB는 브라우저 닫고 OLLAMA_CONTEXT_LENGTH 내리는 실험용.
DeepSeek R1 14B는 돌아가나요?
deepseek-r1:8b는 16GB에서 상시 가능(Swap 약 1GB, 33 tok/s), Qwen3 8B와 동급. 14B급(deepseek-r1:14b 등)은 qwen3:14b와 비슷한 곡선: 24GB면 Swap 0(약 28 tok/s급), 16GB는 장기 Swap으로 약 18 tok/s. 14B 메인이면 24GB, 16GB는 비추.
16GB는 이제 구식인가요?
하루아침에 도태되진 않지만, 2026 기본 부하는 「가끔 ollama run」에서 「브라우저 + IDE + 8B 상시 + Agent」로 옮겼습니다. 16GB에 맞는 건 8B 추론, API 중심, 탭 정리 OK. Claude Code / OpenHuman을 기본 ON에 Swap도 피하려면 16GB는 「입문」에 가깝습니다.
24GB는 몇 년 버틸까요?
현재 페이스(8B–14B 메인, 27B 시험)면 24GB는 약 3–5년 「데스크톱 + 로컬 Agent」 스위트스팟: 14B, 임베딩, 개발 도구 동시. 그 이상(32B+ 상시)은 Mac Studio / 클라우드 GPU 계획. Mac mini는 출고 후 메모리 증설 불가.
Ollama와 MLX 중 메모리에 유리한 쪽은?
일상 대화 추론: Ollama가 다루기 쉽습니다. GGUF + 상시 프로세스 footprint가 예측 가능해 Activity Monitor와 일치. MLX는 로드·컴파일, Xcode 파이프라인 동시에 피크가 날카롭습니다. 평균이 낮아도 순간 상한·Swap. Ollama를 기본 채팅/RAG, MLX는 배치나 전용 노드로.
Mac mini와 RTX 5060, 로컬 AI엔 어느 쪽?
텍스트 8B–14B, Claude Code, iOS 개발: M4 Mac mini(24GB 권장). 통합 메모리 + macOS 툴체인이 강점. Stable Diffusion, 70B 양자화, 게임: RTX 5060. VRAM·CUDA 생태는 Mac mini로 대체 불가. 최종형은 「Mac mini + RTX 또는 클라우드 GPU」 분담이 많습니다.
M4 Mac mini 16GB에서 Qwen3 8B는 충분한가요?
충분합니다. 실측 13.2GB 사용, Swap 약 1.1GB, 34 tok/s, 메모리 압력 노란색. 가끔 끊김 OK면 16GB; Swap 0 데스크톱은 24GB(16.4GB 사용, 37 tok/s).
24GB가 16GB보다 Ollama가 얼마나 빠른가요?
동일 모델 qwen3:8b에서 약 9%(34 vs 37 tok/s)뿐. 24GB 핵심은 Swap 0, 14B·두 번째 소형 모델 여유이지 연산 2배가 아닙니다.
Gemma 3 27B는 24GB Mac mini에서 돌아가나요?
⚠️ 강한 양자화 시험용; 컨텍스트 늘리면 OOM. 8B–14B가 24GB 쾌적 구간. 27B 메인은 RTX나 클라우드 GPU.
AI 때문에 Mac Studio에 돈 쓸 가치가 있나요?
8B–14B + 개발만이면 M4 Mac mini 24GB 가성비가 높습니다. 64GB 통합 메모리, 다중 14B/32B, 무거운 MLX 파이프라인이 필요하면 Mac Studio; 먼저 Cloud Mac으로 메모리 곡선 검증 후 Studio 판단도 합리적.
어떤 메모리 용량을 살지 모르겠어요.
본문 명령으로 8B + 14B 각 30분, Swap·메모리 압력 확인. 실기 없으면 동일 M4 Mac mini 클라우드(24GB)에 Ollama / OpenHuman 올려 일주일 관찰——맹목 증설·RTX 선구매보다 저렴한 경우가 많습니다.
실측 데이터를 재현할 수 있나요?
가능합니다. Ollama 0.12.x, 같은 Chrome/IDE/Slack 시나리오면 절대값 ±10% 정도 흔들리지만, 16GB Swap, 24GB Swap 0, 14B는 24GB 추세는 같아야 합니다.
경험담
메모리 용량이 애매하면? 일주일 먼저 돌려보세요
본문과 같은 부하(Chrome, IDE, qwen3:8b / qwen3:14b)로 Swap과 메모리 압력을 기록하세요. 프로덕션급 전용 macOS에서 대조하려면 ZavCloud M4 Mac mini 클라우드가 구매 전 검증에 적합합니다.