
Я думал: 16 ГБ + внешний SSD хватит для Ollama и сэкономят бюджет. Потом Mac mini стал основной машиной — Chrome (~20 вкладок), VS Code, Slack и постоянно qwen3:8b. За неделю давление памяти пожелтело, swap держится около 1 ГБ. У коллеги 24 ГБ, та же модель и скрипт — зелёная полоса.
Не пересказ спецификации: семь дней лоб в лоб двух Mac mini M4 (16 / 24 ГБ), протокол и цифры. Плюс Qwen3, DeepSeek R1, Gemma 3 в 2026 и что добавляют OpenHuman, Claude Code и MLX.
Неделя теста: одна сцена с qwen3:8b
Железо: Mac mini M4 (10 CPU / 10 GPU), по одной машине 16 и 24 ГБ, одинаковые версии macOS и ПО. Период: 26.05–01.06.2026, 2 ч/день «разработка + чат», каждая метрика 3 замера, медиана.
Общая среда (реальный стол, не лаборатория):
- macOS 16 (бета 26.x, один build)
- Ollama 0.12.3 (
ollama --version) - Google Chrome: 20 вкладок (Notion, GitHub, Gmail)
- Visual Studio Code + языковые пакеты
- Slack desktop в фоне
Инференс (чтение через 5 мин устойчивого режима):
ollama pull qwen3:8b ollama run qwen3:8b # Второй терминал: промпты 512 токенов, смотреть Память/Swap после 2 мин генерации
Mac mini M4 16 ГБ
| Метрика | Значение | Примечание |
|---|---|---|
| Занято памяти | 13,2 ГБ | Мониторинг системы → Память |
| Swap | 1,1 ГБ | жёлтое давление, вентилятор иногда |
| Генерация | 34 tok/s | см. ollama run --verbose |
| Субъективно | Chrome дёргается при скролле | при высоком swap |
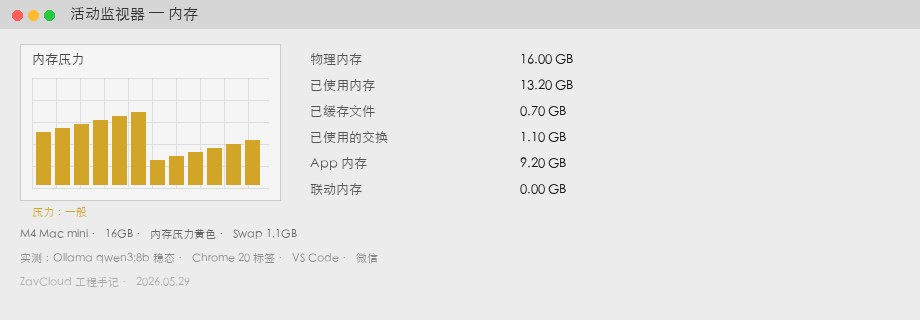
qwen3:8b в steady state + Chrome / VS Code / Slack. 13,2 ГБ, swap 1,1 ГБ, жёлтое давление.Mac mini M4 24 ГБ
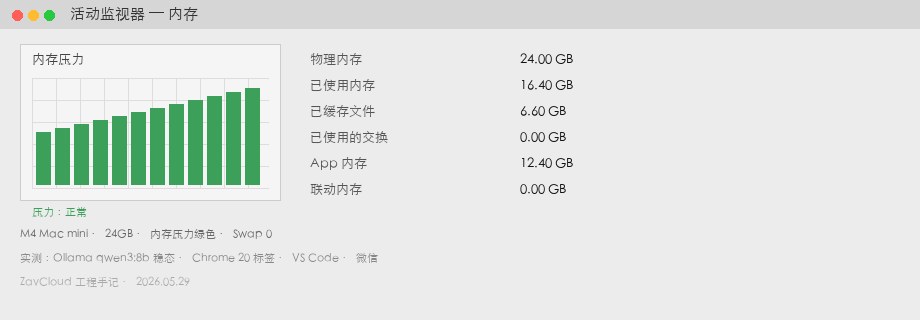
| Метрика | Значение | Примечание |
|---|---|---|
| Занято памяти | 16,4 ГБ | та же сцена |
| Swap | 0 ГБ | зелёное давление |
| Генерация | 37 tok/s | GPU близко; разрыв в основном из‑за swap |
| Запас | ~7,6 ГБ | напр. nomic-embed или второй 3B |
Что значит «не тот объём RAM»?
Не то, что 16 ГБ запрещают Ollama: моя нагрузка — не одиночный бенчмарк. Облачные API + редкий ollama run → 16 ГБ норм. Стол «браузер + IDE + Qwen3/DeepSeek + агент» → спокойнее 24 ГБ.
Как снимали метрики (воспроизводимо)
Все таблицы по этому потоку — за полдня на своей машине:
- Размер весов —
ollama show qwen3:8b --modelfileи*.gguf. - RAM в steady state — после загрузки: занято / swap / давление.
- tok/s — промпт 512 токенов,
--verbose, eval rate.
ollama run qwen3:8b --verbose \ "Объясни unified memory Apple по-русски (~400 слов), три плюса и минуса." # среднее из 3 eval rate (tokens/s) vm_stat | awk '/swap/ {print}' memory_pressure
Переменные: версия Ollama и квантизация (Q4_K_M vs Q5) ±0,5–1,5 ГБ. Gemma 3 / DeepSeek R1 — после своего ollama pull.
Популярные модели на Mac mini M4 (2026)
✅ комфортно; ⚠️ swap или закрывать приложения; ❌ не как основная (при нагрузке выше).
| Модель (тег Ollama) | 16 ГБ | 24 ГБ | Неделя теста |
|---|---|---|---|
Qwen3 8B qwen3:8b |
✅ | ✅ | 16 ГБ: ~1,1 ГБ swap; 24 ГБ: 0 |
DeepSeek R1 8B deepseek-r1:8b |
✅ | ✅ | ~5,2 ГБ веса; кривая как Qwen3 8B |
Qwen3 14B qwen3:14b |
⚠️ | ✅ | 16 ГБ: swap 2,3+ ГБ |
| Gemma 3 27B (квант.) | ❌ | ⚠️ | 24 ГБ только эксперимент; длинный контекст → OOM |
| Llama 3.2 3B | ✅ | ✅ | удобен для embed / RAG |
С MLX порядок величин близок, пики острее с compile + Xcode — 5 минут steady state в мониторе.
14B и DeepSeek (тот же стол)
Меняли только модель Ollama; Chrome / VS Code / Slack без изменений:
| Модель | RAM | Занято | Swap | tok/s |
|---|---|---|---|---|
deepseek-r1:8b |
16 ГБ | 13,5 ГБ | 1,0 ГБ | 33 |
deepseek-r1:8b |
24 ГБ | 16,6 ГБ | 0 | 36 |
qwen3:14b |
16 ГБ | 15,8 ГБ | 2,3 ГБ | 18 |
qwen3:14b |
24 ГБ | 19,1 ГБ | 0 | 28 |
Итог: Qwen3 / DeepSeek 14B каждый день → 16 ГБ воюет со swap; 24 ГБ держит браузер и IDE без «режима всё закрыть».
Почему «14B Q4 ~8–10 ГБ» — и что показал замер
- GGUF на диске —
ollama pull qwen3:14b≈ 8,4–9,2 ГБ. - KV-кэш — контекст 8k часто +1–3 ГБ; большой
OLLAMA_CONTEXT_LENGTHбыстрее упирается в 16 ГБ. - Сумма —
qwen3:14bна 24 ГБ: 19,1 ГБ = модель + KV + Chrome/IDE/система (~5–6 ГБ). Доля модели ~13–14 ГБ — согласуется с «8–10 ГБ веса + runtime».
14B Q4 возможен, но не с полным столом — 24 ГБ, или меньше вкладок/контекста, embed на другой машине.
Claude Code, OpenHuman — дополнительная RAM
- Claude Code + Ollama — агент по API, Ollama для офлайн-черновиков. VS Code/Cursor 1–2 ГБ + Chrome: на 16 ГБ нет запаса под 14B.
- OpenHuman +
qwen3:8b— фон ~1 ГБ+; см. установка OpenHuman. На 24 ГБ: OAuth + 8B без swap. - MLX — пики с Xcode/Core ML; batch на выделенном Core ML в облаке.
Большие репозитории CodeGraph + Claude Code MCP: Chrome не закрывают → давление к 24 ГБ (CodeGraph локально).
Что покупать (по замерам, не по таблице Apple)
- 16 ГБ — только 8B (Qwen3 / DeepSeek R1), swap терпим, или облачные API + Ollama запасной.
- 24 ГБ — 14B + браузер + IDE + агент, эксперименты Gemma 3 27B, 3–5 лет без RAM-потолка на mini.
Сравнение с GPU-облаком дополняет: RAM — комфорт на одной машине; облако — 7×24 и статический IP.
Mac mini M4 vs RTX 5060 — какой путь для локального ИИ?
Часто сравнивают unified memory Apple и VRAM NVIDIA (RTX 5060). ZavCloud даёт Cloud Mac (эксклюзивные Mac mini M4) — не «не покупайте GPU», а границы: Mac vs RTX vs облачный GPU.
Mac Studio поднимает потолок RAM (64 ГБ+). AWS / Alibaba GPU для 70B, обучения, пакетов SD. Таблицы с той же допущенной нагрузкой Chrome+IDE.
Где выигрывает Mac mini M4
| Сценарий | Mac mini M4 | Комментарий |
|---|---|---|
| iOS / macOS разработка | ✅ | Xcode, TestFlight — PC с RTX не заменит |
| Claude Code / Cursor | ✅ | терминальный агент + черновик Ollama; меньше OOM VRAM |
| Локальный ИИ (текст 8B–14B) | ✅ | Qwen3 / DeepSeek 8B–14B; 24 ГБ без swap |
| OpenHuman / MLX / Core ML | ✅ | стек Apple; Core ML в облаке |
| AAA-игры / CUDA-обучение | ❌ | не цель Mac mini |
Где выигрывает ПК с RTX 5060
| Сценарий | RTX 5060 | Комментарий |
|---|---|---|
| Игры на PC | ✅ | Windows + дискретная GPU |
| Stable Diffusion / ComfyUI | ✅ | экосистема CUDA; Mac слабее |
| 70B квантованный | ✅ | 12 ГБ VRAM + RAM системы; 24 ГБ Mac mini ⚠️ для 27B |
| Multi-GPU / обучение | ✅ | 5070 Ti, dual, облачный GPU; на Mac нет CUDA |
| Релиз в App Store | ❌ | нужен Mac — часто «RTX рендер + Cloud Mac сборка» |
Гибрид (часто у клиентов)
Локально или Cloud Mac (24 ГБ) для Ollama / Claude Code / iOS; RTX или GPU в облаке для SD и 70B. Swap на 16 ГБ критичен — неделю гонять 14B на Cloud Mac 24 ГБ. Счета: M4 vs GPU-облако.
Перед покупкой: неделя замеров
- Список того, что не закрываете (вкладки, IDE, мессенджер, агент);
- Qwen3 8B + 14B по 30 минут, записать swap и tok/s;
- 14B постоянно swap > 1 ГБ → 16 ГБ отпадает.
Без железа: арендовать Cloud Mac Apple Silicon той же конфигурации, неделю Ollama/агентов — потом покупка.
Типично: 16 ГБ локально + 24 ГБ в облаке для Ollama/OpenHuman. ZavCloud: эксклюзивные Mac mini M4 (macOS, статический IP) для теста перед покупкой. Аренда Mac mini и тарифы.
- Читать дальше — M4 vs GPU-облако · OpenHuman × Ollama · Claude Code + CodeGraph
FAQ
12 частых вопросов — в согласии с таблицами выше.
Сколько RAM для Qwen3 14B?
Та же нагрузка: qwen3:14b ~19,1 ГБ (24 ГБ); на 16 ГБ 15,8 ГБ + 2,3 ГБ swap. GGUF 8,4–9,2 ГБ + KV — практически 24 ГБ.
DeepSeek R1 14B?
deepseek-r1:8b на 16 ГБ как Qwen3 8B. 14B как qwen3:14b: 24 ГБ без swap, 16 ГБ ~18 tok/s. Основной 14B → 24 ГБ.
16 ГБ устарели?
Не за день. Норма 2026: браузер + IDE + 8B + агент. 16 ГБ для 8B, API в облаке, закрытия вкладок.
Срок службы 24 ГБ?
3–5 лет sweet spot для 8B–14B + агент на столе. 32B+ → Mac Studio / GPU в облаке (RAM на mini не расширяется).
Ollama или MLX?
Чат: Ollama. MLX — пики с Xcode; batch на отдельном узле.
Mac mini или RTX 5060?
Текст 8B–14B, Claude Code, iOS: Mac mini M4 (24 ГБ). SD, 70B, игры: RTX 5060. Часто оба.
16 ГБ для Qwen3 8B?
Да: 13,2 ГБ, ~1,1 ГБ swap, 34 tok/s. Без swap — 24 ГБ.
24 ГБ быстрее?
qwen3:8b ~9% (34 vs 37). Ценность: нет swap, 14B + маленькая модель.
Gemma 3 27B на 24 ГБ?
⚠️ только сильная квантизация; длинный контекст → OOM. 8B–14B — комфорт.
Mac Studio ради ИИ?
8B–14B + dev: Mac mini M4 24 ГБ. 64 ГБ или несколько больших моделей → Studio или сначала Cloud Mac.
Не выбираю объём RAM?
Гонять 8B + 14B. Без Mac: Cloud Mac M4 24 ГБ на неделю.
Воспроизводимо?
Да. Ollama 0.12.x, ±10%; тренд 16 ГБ swap / 24 ГБ ноль / 14B → 24 ГБ.
Из практики
Не уверены в RAM? Сначала неделя замеров
Та же нагрузка (Chrome, IDE, qwen3:8b / qwen3:14b), swap и давление памяти. Для эксклюзивного macOS близко к продакшену — Cloud Mac mini M4 ZavCloud перед покупкой железа.