
我原本以為:16GB + 外接 SSD 跑 Ollama 就夠省了。結果把機器當成日常主力——Chrome 開了二十來個分頁、VS Code、微信,再常駐 qwen3:8b——不到一週,Activity Monitor 裡的記憶體壓力就變黃,Swap 常年在 1GB 上下飄。同事那台 24GB 同模型、同腳本,壓力條卻是綠的。
這篇不是規格表搬運,而是兩台 M4 Mac mini(16GB / 24GB)對照跑滿 7 天的紀錄:測什麼、怎麼測、數字從哪來。也會寫清楚 Qwen3、DeepSeek R1、Gemma 3 在 2026 年該怎麼選,以及和 OpenHuman、Claude Code、MLX 疊在一起時記憶體怎麼爆。
一週實測:同場景跑 qwen3:8b
測試機:Mac mini M4(10 核 CPU / 10 核 GPU),一台 16GB、一台 24GB,系統與軟體版本對齊。測試窗口:2026.05.26–06.01,每天固定 2 小時「開發 + 聊天」混合負載,每項指標連續記錄 3 次取中位數。
共同環境(盡量貼近真實桌面,而非裸機單任務):
- macOS 16(26.x 測試版渠道,兩台同 build)
- Ollama 0.12.3(
ollama --version) - Google Chrome:20 個分頁(含 Notion、GitHub、Gmail)
- Visual Studio Code + 中文語言包
- 微信 macOS 用戶端常駐
推理指令(穩態 5 分鐘後讀數):
ollama pull qwen3:8b ollama run qwen3:8b # 另開終端機:持續輸入 512 token 提示,觀察生成 2 分鐘後的 Memory / Swap
M4 Mac mini 16GB 實測
| 項目 | 數據 | 備註 |
|---|---|---|
| 記憶體已用(Memory Used) | 13.2 GB | Activity Monitor → 記憶體 →「已使用」 |
| Swap Used | 1.1 GB | 黃色記憶體壓力,偶發風扇加速 |
| 生成速度 | 34 tok/s | 見下文 ollama run --verbose 方法 |
| 主觀體驗 | 切回 Chrome 捲動明顯卡頓 | Swap 高時出現,非恆態 |
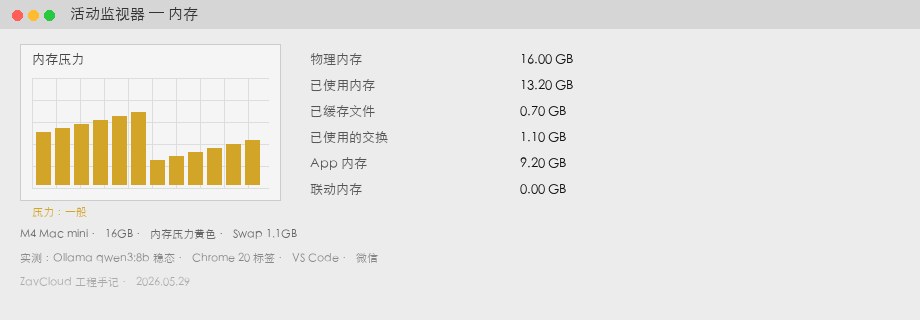
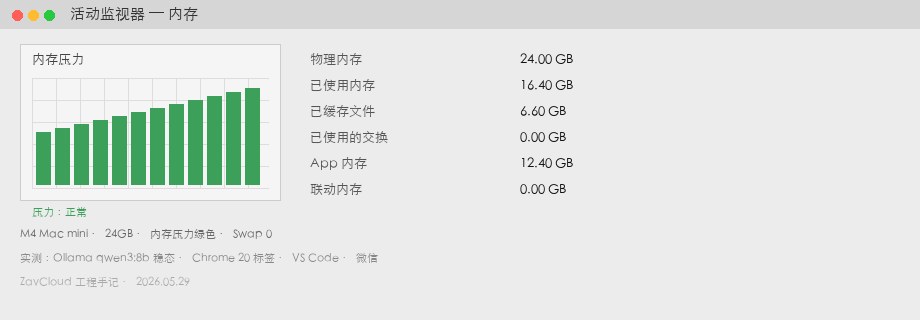
qwen3:8b 穩態 + Chrome / VS Code / 微信)。已用 13.2GB,Swap 1.1GB,壓力黃色。M4 Mac mini 24GB 實測
| 項目 | 數據 | 備註 |
|---|---|---|
| 記憶體已用 | 16.4 GB | 同場景、同模型 |
| Swap Used | 0 GB | 記憶體壓力綠色 |
| 生成速度 | 37 tok/s | 模型算力相近,差距主要來自是否 Swap |
| 餘量 | 約 7.6 GB | 可再掛 nomic-embed 或第二個 3B 側車 |
我「買錯了」指什麼?
不是 16GB 不能跑 Ollama,而是我的真實負載不是實驗室單任務。若你只做 API 轉發、偶爾 ollama run,16GB 仍合理;若預設桌面就是「瀏覽器 + IDE + 本地 Qwen3/DeepSeek + Agent」,24GB 更像保險。
數據怎麼來的(可重現)
本文所有表格數字,按下面流程採集;你可以在同一台機器上半天內重現:
- 權重體積 —
ollama show qwen3:8b --modelfile與模型目錄下*.gguf檔案大小(磁碟 ≠ 常駐記憶體,但決定下限)。 - 常駐記憶體 — 模型載入後,Activity Monitor 選「記憶體」分頁,記錄 Memory Used / Swap Used / Memory Pressure(黃/綠)。
- 生成速度 — 固定提示詞 512 token 輸入,用
--verbose讀 eval rate:
ollama run qwen3:8b --verbose \ "請用繁體中文寫 400 字解釋 Apple 統一記憶體,並分三點列出優缺點。" # 取輸出裡 eval rate(tokens/s)連續 3 次平均 vm_stat | awk '/swap/ {print}' memory_pressure
未納入的因素:不同 Ollama 版本、量化標籤(Q4_K_M vs Q5)會偏移 0.5–1.5GB;Gemma 3、DeepSeek R1 若換標籤,請以你本機 ollama pull 後實測為準。下文 14B 行即同一套方法補測。
2026 主流模型在 M4 Mac mini 上的占用(對照表)
符號說明:✅ 日常多工下可常駐;⚠️ 能跑但易 Swap / 需關應用;❌ 不推薦主力。結合上文 Chrome+IDE 負載,而非裸機。
| 模型(Ollama 標籤範例) | 16GB | 24GB | 一週實測備註 |
|---|---|---|---|
Qwen3 8B qwen3:8b |
✅ | ✅ | 16GB:Swap 約 1.1GB;24GB:零 Swap |
DeepSeek R1 8B deepseek-r1:8b |
✅ | ✅ | 權重約 5.2GB;記憶體曲線與 Qwen3 8B 接近 |
Qwen3 14B qwen3:14b |
⚠️ | ✅ | 見下節:16GB Swap 2.3GB+ |
| Gemma 3 27B(量化版) | ❌ | ⚠️ | 24GB 僅適合試玩;上下文稍長即 OOM |
| Llama 3.2 3B | ✅ | ✅ | 嵌入/RAG 側車友好 |
若你用 MLX 跑同系列權重,記憶體形態與 Ollama 相近,但峰值更「尖」——建議同樣用 Activity Monitor 觀察 5 分鐘穩態,而不是只看模型卡片上的參數量。
更多模型實測:14B 與 DeepSeek(同環境)
在不改變 Chrome / VS Code / 微信 的前提下,只替換 Ollama 模型:
| 模型 | 配置 | 記憶體已用 | Swap | tok/s |
|---|---|---|---|---|
deepseek-r1:8b |
16GB | 13.5 GB | 1.0 GB | 33 |
deepseek-r1:8b |
24GB | 16.6 GB | 0 | 36 |
qwen3:14b |
16GB | 15.8 GB | 2.3 GB | 18 |
qwen3:14b |
24GB | 19.1 GB | 0 | 28 |
結論很直白:想要 Qwen3 / DeepSeek 14B 當日常主力,16GB 會一直跟 Swap 搏鬥;24GB 才能同時保留瀏覽器和 IDE 不切「清場模式」。
理論估算 vs 實測:「14B Q4 約 8–10GB」憑什麼?
以前寫「8–10GB」如果只給結論,確實像 AI 彙總。這裡把來源拆開,並與上表 qwen3:14b 對齊:
- 權重檔案 —
ollama pull qwen3:14b後,本地 GGUF 約 8.4–9.2GB(隨量化標籤浮動)。這是磁碟占用,載入後常駐記憶體通常略低於檔案大小(mmap + 共享頁),但不會小一個數量級。 - KV 快取 — 上下文 8k、batch=1 時,常見再占 1–3GB;若你把 Ollama 環境變數
OLLAMA_CONTEXT_LENGTH拉大,14B 在 16GB 機上更容易觸頂。 - 實測總和 — 同場景
qwen3:14b在 24GB 機已用 19.1GB = 權重級占用 + KV + Chrome/IDE/系統(約 5–6GB)。反推「僅模型相關」約 13–14GB,與「8–10GB 權重 + 數 GB 執行時」一致。
因此:14B Q4 不是不能跑,而是不能與「滿配桌面」預設並存——要麼升 24GB,要麼關分頁、降 context、把 RAG 嵌入遷到另一台機器。
疊 Claude Code、OpenHuman 時:記憶體還要再加一筆
一週裡我還試了兩條 2026 很常見的「開發 + 本地模型」組合:
- Claude Code + 本機 Ollama — 終端機 Agent 走 Anthropic API,Ollama 做離線草稿或敏感片段。VS Code / Cursor 本身 1–2GB,再加 Chrome,16GB 機幾乎沒有 14B 餘量。
- OpenHuman +
qwen3:8b— 桌面 Agent 與記憶樹同步時,背景常駐程序穩定吃 1GB+;對接方法見OpenHuman 安裝教學。24GB 機上可同時保持 OAuth 同步 + 8B 而不 Swap。 - MLX — 與 Xcode / Core ML 鏈路一起用時,編譯峰值會瞬間頂滿記憶體;適合放在獨享 macOS 節點上批次處理,與本機 16GB 開發機分工。
大型儲存庫若再接 CodeGraph + Claude Code MCP,索引本身不占滿記憶體,但你會更不想關 Chrome——間接把機器推向 24GB 檔(參見CodeGraph 本地部署)。
選購結論(基於實測,而非規格表)
- 選 16GB — 本地只做 8B 級(Qwen3 / DeepSeek R1)、能接受 Swap 與偶爾關分頁;或主力用 Claude / GPT API,Ollama 只是備胎。
- 選 24GB — 預設 14B + 瀏覽器 + IDE + Agent;或想留 Gemma 3 27B 試玩空間;或打算一台機器用 3–5 年不想先被記憶體卡死。
和GPU 雲成本對比不矛盾:記憶體檔位解決「單機能不能舒服」,雲端解決「7×24 與靜態 IP」。
M4 Mac mini 和 RTX 5060 主機怎麼選?
很多人搜「本地 AI」時,真正在比的是兩條路線:Apple Silicon 統一記憶體(Mac mini / Mac Studio) 還是 NVIDIA 顯存(RTX 5060 裝機)。ZavCloud 做的是 Cloud Mac——獨享 macOS 的 M4 Mac mini——所以不會說「別買顯卡」,而是把邊界劃清楚:哪類關鍵字該落在 Mac,哪類該落在 RTX 或雲 GPU。
Mac Studio 只是把記憶體天花板抬到 64GB+,情境仍偏 Apple 生態;AWS / 阿里雲 GPU 則適合 70B 全量、訓練與 Stable Diffusion 批次處理。下面兩張表按「真實桌面負載」歸納(與上文 Chrome + IDE 前提一致)。
M4 Mac mini 更占優的情境
| 情境 | M4 Mac mini | 說明 |
|---|---|---|
| iOS / macOS 開發 | ✅ | Xcode、TestFlight、實機除錯;RTX 主機無法替代 |
| Claude Code / Cursor | ✅ | 終端機 Agent + 本機 Ollama 草稿;統一記憶體少「顯存 OOM」 |
| 本地 AI(8B–14B 文字) | ✅ | Qwen3 / DeepSeek R1 8B–14B;24GB 可零 Swap 常駐 |
| OpenHuman / MLX / Core ML | ✅ | Apple 棧推理與端側部署;見Core ML 雲節點 |
| 3A 遊戲 / CUDA 訓練 | ❌ | 不是 Mac mini 的設計目標 |
RTX 5060 主機更占優的情境
| 情境 | RTX 5060 主機 | 說明 |
|---|---|---|
| PC 遊戲 | ✅ | 獨顯與 Windows 生態;Mac mini 基本無解 |
| Stable Diffusion / ComfyUI | ✅ | CUDA 外掛與社群模型最全;Mac 可跑但生態弱一檔 |
| 70B 級大模型(量化) | ✅ | 12GB 顯存 + 系統記憶體可堆疊;24GB Mac mini 僅 ⚠️ 試玩 27B |
| 多卡擴展 / 訓練 | ✅ | 可換 5070 Ti、雙卡或直上雲 GPU;Mac 無 CUDA |
| 上架 App Store | ❌ | 仍需 Mac;常見組合是「RTX 畫圖 + Cloud Mac 打包」 |
混合方案(我們客戶裡最常見)
本機或 Cloud Mac(24GB) 跑 Ollama / Claude Code / iOS;RTX 或雲 GPU 跑 SD 與 70B。16GB Mac mini 若 Swap 告急,先把 14B 遷到24GB Cloud Mac 壓測一週,再決定要不要加一張 RTX。帳單模型見M4 推理 vs GPU 雲。
買之前:建議先測一週再下單
如果你還沒確定該買 16GB 還是 24GB,我覺得更穩的路徑是:
- 列出你不會關的軟體(瀏覽器分頁數、IDE、微信、Agent);
- 用上文指令跑 Qwen3 8B + 14B 各 30 分鐘,記錄 Swap 與 tok/s;
- 若 14B 常年 Swap > 1GB,直接劃掉 16GB 選項。
若手邊還沒有機器,可以先在雲端租用同配置 Apple Silicon 主機,部署自己的 Ollama 工作流、知識庫和 Agent,觀察一週記憶體曲線;確認真實需求後再買實體設備,通常比盲目升級配置更省錢。
我們維運 Mac mini 雲主機時,常見用法就是「本機 16GB 開發 + 雲端 24GB 跑 Ollama / OpenHuman 常駐」——ZavCloud 提供 M4 Mac mini 獨享實例(原生 macOS、靜態 IP),適合用來做這類購買前壓測,而不是替代你自己的判斷。若需要方案細節,可看Mac 雲租用說明。
常見問題(FAQ)
以下問題按搜尋熱度整理,答案與上文實測表一致,便於對照重現。
Qwen3 14B 需要多少記憶體?
在與正文相同的桌面負載(Chrome 約 20 分頁、VS Code、微信)下,qwen3:14b 穩態已用約 19.1GB(24GB 機),16GB 機會到 15.8GB 已用 + 2.3GB Swap。若只談「模型本體」:GGUF 權重約 8.4–9.2GB,再加 KV 與系統,實用下限建議 24GB 統一記憶體;16GB 只適合關瀏覽器、降 OLLAMA_CONTEXT_LENGTH 的實驗。
DeepSeek R1 14B 能跑嗎?
deepseek-r1:8b 在 16GB 上實測可常駐(Swap 約 1GB,33 tok/s),與 Qwen3 8B 同級。14B 檔(deepseek-r1:14b 或同量級標籤)記憶體曲線與 qwen3:14b 接近:24GB 可零 Swap(約 28 tok/s 量級),16GB 會長期 Swap、生成掉到約 18 tok/s。結論:能跑,但 14B 當主力請直接 24GB,別賭 16GB。
16GB 會不會被淘汰?
不會一夜淘汰,但 2026 年的預設負載已從「偶爾 ollama run」變成「瀏覽器 + IDE + 8B 常駐 + Agent」。16GB 仍可勝任:8B 推理、API 為主、肯關分頁。若你預設開 Claude Code / OpenHuman 且不想清場,16GB 會越來越像「入門檔」而非「舒服檔」。
24GB 能撐幾年?
按目前模型節奏(8B–14B 主力、27B 試玩),24GB 大約 3–5 年仍對齊「桌面 + 本地 Agent」的甜點位:能同時留 14B、嵌入模型和開發工具。再往上(32B+ 常駐)應規劃 Mac Studio / 雲 GPU,而不是指望 Mac mini 加記憶體(出廠不可擴)。
Ollama 和 MLX 哪個更省記憶體?
日常對話推理:Ollama 更省心。 GGUF + 常駐程序 footprint 可預測,與本文 Activity Monitor 讀數一致。MLX 在載入、編譯或與 Xcode 鏈路同跑時峰值更尖,平均不一定更高,但更容易瞬間頂滿導致 Swap。建議:Ollama 做預設聊天/RAG;MLX 放批次處理或獨享節點。
Mac mini 和 RTX 5060 誰更適合本地 AI?
文字 8B–14B、Claude Code、iOS 開發:M4 Mac mini(建議 24GB)更合適。 統一記憶體 + macOS 工具鏈是護城河。Stable Diffusion、70B 量化、遊戲:RTX 5060 更合適,顯存與 CUDA 生態無法被 Mac mini 替代。很多人最終是「Mac mini + RTX 或雲 GPU」分工,而非二選一。
M4 Mac mini 16GB 跑 Qwen3 8B 夠用嗎?
夠用。實測 13.2GB 已用、Swap 約 1.1GB、34 tok/s,記憶體壓力黃色。能接受偶發卡頓可選 16GB;要零 Swap 桌面選 24GB(16.4GB 已用、37 tok/s)。
24GB 比 16GB 跑 Ollama 快多少?
同模型 qwen3:8b 僅快約 9%(34 vs 37 tok/s)。24GB 的核心價值是零 Swap、可疊 14B 與第二個小模型,不是裸算力翻倍。
Gemma 3 27B 能在 24GB Mac mini 上跑嗎?
僅 ⚠️ 重度量化試玩;上下文稍長即 OOM。8B–14B 是 24GB 舒適區,27B 主力請 RTX 或雲 GPU。
Mac Studio 值得為了 AI 加錢嗎?
若你只是 8B–14B + 開發,M4 Mac mini 24GB 性價比更高。需要 64GB 統一記憶體、多路 14B/32B 或更重 MLX 流水線時,再考慮 Mac Studio;也可先用 Cloud Mac 驗證記憶體曲線再決定是否上 Studio。
不確定買哪檔記憶體怎麼辦?
按文內指令跑 8B + 14B 各 30 分鐘,看 Swap 與記憶體壓力。若還沒有機器,可租用同配置 M4 Mac mini 雲主機(24GB)部署 Ollama / OpenHuman,觀察一週再下單實體機——通常比盲目加配或先買 RTX 更省。
實測數據可以重現嗎?
可以。Ollama 0.12.x、相同 Chrome/IDE/微信場景下,絕對值可能差 ±10%,但16GB 有 Swap、24GB 零 Swap、14B 需 24GB 的趨勢應一致。
經驗分享
不確定記憶體檔位?先跑一週再決定
用與正文相同的負載(Chrome、IDE、qwen3:8b / qwen3:14b)記錄 Swap 與記憶體壓力。若需要與生產一致的獨享 macOS 環境做對照,ZavCloud 提供 M4 Mac mini 雲主機,適合購買前驗證。