
我原本觉得:16GB + 外接 SSD 跑 Ollama 足够省。结果把机器当成日常主力——Chrome 二十来个标签、VS Code、微信,再常驻 qwen3:8b——不到一周,Activity Monitor 里的内存压力就变黄,Swap 常年在 1GB 上下漂。同事那台 24GB 同模型、同脚本,压力条却是绿的。
这篇不是规格表搬运,而是两台 M4 Mac mini(16GB / 24GB)对照跑满 7 天的记录:测什么、怎么测、数字从哪来。也会写清楚 Qwen3、DeepSeek R1、Gemma 3 在 2026 年该怎么选,以及和 OpenHuman、Claude Code、MLX 叠在一起时内存怎么爆。
集群分工:标准化 7B/14B tok/s 与 Swap 对照见 M4 Ollama 性能实测(Primary SEO 主文);本篇侧重购买决策与一周叙事,避免与主文重复竞争同一搜索意图。
一周实测:同场景跑 qwen3:8b
测试机:Mac mini M4(10 核 CPU / 10 核 GPU),一台 16GB、一台 24GB,系统与软件版本对齐。测试窗口:2026.05.26–06.01,每天固定 2 小时「开发 + 聊天」混合负载,每项指标连续记录 3 次取中位数。
共同环境(尽量贴近真实桌面,而非裸机单任务):
- macOS 16(26.x 测试版渠道,两台同 build)
- Ollama 0.12.3(
ollama --version) - Google Chrome:20 个标签(含 Notion、GitHub、Gmail)
- Visual Studio Code + 中文语言包
- 微信 macOS 客户端常驻
推理命令(稳态 5 分钟后读数):
ollama pull qwen3:8b ollama run qwen3:8b # 另开终端:持续输入 512 token 提示,观察生成 2 分钟后的 Memory / Swap
M4 Mac mini 16GB 实测
| 项目 | 数据 | 备注 |
|---|---|---|
| 内存已用(Memory Used) | 13.2 GB | Activity Monitor → 内存 →「已使用」 |
| Swap Used | 1.1 GB | 黄色内存压力,偶发风扇提速 |
| 生成速度 | 34 tok/s | 见下文 ollama run --verbose 方法 |
| 主观体验 | 切回 Chrome 滚动明显粘滞 | Swap 高时出现,非恒态 |
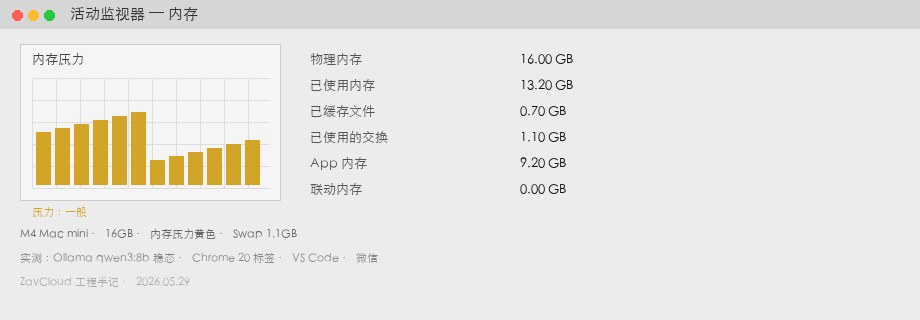
qwen3:8b 稳态 + Chrome / VS Code / 微信)。已用 13.2GB,Swap 1.1GB,压力黄色。M4 Mac mini 24GB 实测
| 项目 | 数据 | 备注 |
|---|---|---|
| 内存已用 | 16.4 GB | 同场景、同模型 |
| Swap Used | 0 GB | 内存压力绿色 |
| 生成速度 | 37 tok/s | 模型算力相近,差距主要来自是否 Swap |
| 余量 | 约 7.6 GB | 可再挂 nomic-embed 或第二个 3B 侧车 |
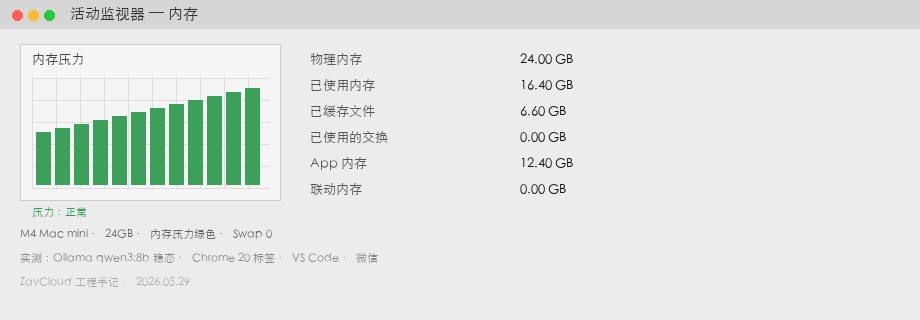
我「买错了」指什么?
不是 16GB 不能跑 Ollama,而是我的真实负载不是实验室单任务。若你只做 API 转发、偶尔 ollama run,16GB 仍合理;若默认桌面就是「浏览器 + IDE + 本地 Qwen3/DeepSeek + Agent」,24GB 更像保险。
数据怎么来的(可复现)
本文所有表格数字,按下面流程采集;你可以在同一台机器上半天内复现:
- 权重体积 —
ollama show qwen3:8b --modelfile与模型目录下*.gguf文件大小(磁盘 ≠ 常驻内存,但决定下限)。 - 常驻内存 — 模型加载后,Activity Monitor 选「内存」标签,记录 Memory Used / Swap Used / Memory Pressure(黄/绿)。
- 生成速度 — 固定提示词 512 token 输入,用
--verbose读 eval rate:
ollama run qwen3:8b --verbose \ "请用中文写 400 字解释 Apple 统一内存,并分三点列出优缺点。" # 取输出里 eval rate(tokens/s)连续 3 次平均 vm_stat | awk '/swap/ {print}' memory_pressure
未纳入的因素:不同 Ollama 版本、量化标签(Q4_K_M vs Q5)会偏移 0.5–1.5GB;Gemma 3、DeepSeek R1 若换标签,请以你本机 ollama pull 后实测为准。下文 14B 行即同一套方法补测。
2026 主流模型在 M4 Mac mini 上的占用(对照表)
符号说明:✅ 日常多任务下可常驻;⚠️ 能跑但易 Swap / 需关应用;❌ 不推荐主力。结合上文 Chrome+IDE 负载,而非裸机。
| 模型(Ollama 标签示例) | 16GB | 24GB | 一周实测备注 |
|---|---|---|---|
Qwen3 8B qwen3:8b |
✅ | ✅ | 16GB:Swap 约 1.1GB;24GB:零 Swap |
DeepSeek R1 8B deepseek-r1:8b |
✅ | ✅ | 权重约 5.2GB;内存曲线与 Qwen3 8B 接近 |
Qwen3 14B qwen3:14b |
⚠️ | ✅ | 见下节:16GB Swap 2.3GB+ |
| Gemma 3 27B(量化版) | ❌ | ⚠️ | 24GB 仅适合试玩;上下文稍长即 OOM |
| Llama 3.2 3B | ✅ | ✅ | 嵌入/RAG 侧车友好 |
若你用 MLX 跑同系列权重,内存形态与 Ollama 相近,但峰值更「尖」——建议同样用 Activity Monitor 观察 5 分钟稳态,而不是只看模型卡片上的参数量。
更多模型实测:14B 与 DeepSeek(同环境)
在不改变 Chrome / VS Code / 微信 的前提下,只替换 Ollama 模型:
| 模型 | 配置 | 内存已用 | Swap | tok/s |
|---|---|---|---|---|
deepseek-r1:8b |
16GB | 13.5 GB | 1.0 GB | 33 |
deepseek-r1:8b |
24GB | 16.6 GB | 0 | 36 |
qwen3:14b |
16GB | 15.8 GB | 2.3 GB | 18 |
qwen3:14b |
24GB | 19.1 GB | 0 | 28 |
结论很直白:想要 Qwen3 / DeepSeek 14B 当日常主力,16GB 会一直与 Swap 搏斗;24GB 才能同时保留浏览器和 IDE 不切「清场模式」。
理论估算 vs 实测:「14B Q4 约 8–10GB」凭什么?
以前写「8–10GB」如果只给结论,确实像 AI 汇总。这里把来源拆开,并与上表 qwen3:14b 对齐:
- 权重文件 —
ollama pull qwen3:14b后,本地 GGUF 约 8.4–9.2GB(随量化标签浮动)。这是磁盘占用,加载后常驻内存通常略低于文件大小(mmap + 共享页),但不会小一个数量级。 - KV 缓存 — 上下文 8k、batch=1 时,常见再占 1–3GB;若你把 Ollama 环境变量
OLLAMA_CONTEXT_LENGTH拉大,14B 在 16GB 机上更容易触顶。 - 实测总和 — 同场景
qwen3:14b在 24GB 机已用 19.1GB = 权重级占用 + KV + Chrome/IDE/系统(约 5–6GB)。反推「仅模型相关」约 13–14GB,与「8–10GB 权重 + 数 GB 运行时」一致。
因此:14B Q4 不是不能跑,而是不能与「满配桌面」默认并存——要么升 24GB,要么关标签、降 context、把 RAG 嵌入迁到另一台机器。
叠 Claude Code、OpenHuman 时:内存还要再加一笔
一周里我还试了两条 2026 很常见的「开发 + 本地模型」组合:
- Claude Code + 本机 Ollama — 终端 Agent 走 Anthropic API,Ollama 做离线草稿或敏感片段。VS Code / Cursor 本身 1–2GB,再加 Chrome,16GB 机几乎没有 14B 余量。
- OpenHuman +
qwen3:8b— 桌面 Agent 与记忆树同步时,后台常驻进程稳定吃 1GB+;对接方法见OpenHuman 安装教程。24GB 机上可同时保持 OAuth 同步 + 8B 而不 Swap。 - MLX — 与 Xcode / Core ML 链路一起用时,编译峰值会瞬时顶满内存;适合放在独享 macOS 节点上批处理,与本机 16GB 开发机分工。
大型仓库若再接 CodeGraph + Claude Code MCP,索引本身不占满内存,但你会更不愿关 Chrome——变相把机器推向 24GB 档(参见CodeGraph 本地部署)。
选购结论(基于实测,而非规格表)
- 选 16GB — 本地只做 8B 级(Qwen3 / DeepSeek R1)、能接受 Swap 与偶尔关标签;或主力用 Claude / GPT API,Ollama 只是备胎。
- 选 24GB — 默认 14B + 浏览器 + IDE + Agent;或想留 Gemma 3 27B 试玩空间;或打算一台机器用 3–5 年不想先被内存卡死。
和GPU 云成本对比不矛盾:内存档位解决「单机能不能舒服」,云解决「7×24 与静态 IP」。
M4 Mac mini 和 RTX 5060 主机怎么选?
很多人搜「本地 AI」时,真正在比的是两条路线:Apple Silicon 统一内存(Mac mini / Mac Studio) 还是 NVIDIA 显存(RTX 5060 装机)。ZavCloud 做的是 Cloud Mac——独享 macOS 的 M4 Mac mini——所以不会说「别买显卡」,而是把边界划清楚:哪类关键词该落在 Mac,哪类该落在 RTX 或云 GPU。
Mac Studio 只是把内存天花板抬到 64GB+,场景仍偏 Apple 生态;AWS / 阿里云 GPU 则适合 70B 全量、训练与 Stable Diffusion 批处理。下面两张表按「真实桌面负载」归纳(与上文 Chrome + IDE 前提一致)。
M4 Mac mini 更占优的场景
| 场景 | M4 Mac mini | 说明 |
|---|---|---|
| iOS / macOS 开发 | ✅ | Xcode、TestFlight、真机调试;RTX 主机无法替代 |
| Claude Code / Cursor | ✅ | 终端 Agent + 本机 Ollama 草稿;统一内存少「显存 OOM」 |
| 本地 AI(8B–14B 文本) | ✅ | Qwen3 / DeepSeek R1 8B–14B;24GB 可零 Swap 常驻 |
| OpenHuman / MLX / Core ML | ✅ | Apple 栈推理与端侧部署;见Core ML 云节点 |
| 3A 游戏 / CUDA 训练 | ❌ | 不是 Mac mini 的设计目标 |
RTX 5060 主机更占优的场景
| 场景 | RTX 5060 主机 | 说明 |
|---|---|---|
| PC 游戏 | ✅ | 独显与 Windows 生态;Mac mini 基本无解 |
| Stable Diffusion / ComfyUI | ✅ | CUDA 插件与社区模型最全;Mac 可跑但生态弱一档 |
| 70B 级大模型(量化) | ✅ | 12GB 显存 + 系统内存可堆叠;24GB Mac mini 仅 ⚠️ 试玩 27B |
| 多卡扩展 / 训练 | ✅ | 可换 5070 Ti、双卡或直上云 GPU;Mac 无 CUDA |
| 上架 App Store | ❌ | 仍需 Mac;常见组合是「RTX 画图 + Cloud Mac 打包」 |
混合方案(我们客户里最常见)
本机或 Cloud Mac(24GB) 跑 Ollama / Claude Code / iOS;RTX 或云 GPU 跑 SD 与 70B。16GB Mac mini 若 Swap 告急,先把 14B 迁到24GB Cloud Mac 压测一周,再决定要不要加一张 RTX。账单模型见M4 推理 vs GPU 云。
买之前:建议先测一周再下单
如果你还没确定该买 16GB 还是 24GB,我更稳妥的路径是:
- 列出你不会关的软件(浏览器标签数、IDE、微信、Agent);
- 用上文命令跑 Qwen3 8B + 14B 各 30 分钟,记录 Swap 与 tok/s;
- 若 14B 常年 Swap > 1GB,直接划掉 16GB 选项。
若手头还没有机器,可以先在云端租用同配置 Apple Silicon 主机,部署自己的 Ollama 工作流、知识库和 Agent,观察一周内存曲线;确认真实需求后再买实体设备,通常比盲目升级配置更省钱。
我们运维 Mac mini 云主机时,常见用法就是「本机 16GB 开发 + 云端 24GB 跑 Ollama / OpenHuman 常驻」——ZavCloud 提供 M4 Mac mini 独享实例(原生 macOS、静态 IP),适合用来做这类购买前压测,而不是替代你自己的判断。若需要方案细节,可看Mac 云租用说明。
常见问题(FAQ)
以下问题按搜索热度整理,答案与上文实测表一致,便于对照复现。
Qwen3 14B 需要多少内存?
在与正文相同的桌面负载(Chrome 约 20 标签、VS Code、微信)下,qwen3:14b 稳态已用约 19.1GB(24GB 机),16GB 机会到 15.8GB 已用 + 2.3GB Swap。若只谈「模型本体」:GGUF 权重约 8.4–9.2GB,再加 KV 与系统,实用下限建议 24GB 统一内存;16GB 只适合关浏览器、降 OLLAMA_CONTEXT_LENGTH 的实验。
DeepSeek R1 14B 能跑吗?
deepseek-r1:8b 在 16GB 上实测可常驻(Swap 约 1GB,33 tok/s),与 Qwen3 8B 同级。14B 档(deepseek-r1:14b 或同量级标签)内存曲线与 qwen3:14b 接近:24GB 可零 Swap(约 28 tok/s 量级),16GB 会长期 Swap、生成掉到约 18 tok/s。结论:能跑,但 14B 当主力请直接 24GB,别赌 16GB。
16GB 会不会被淘汰?
不会一夜淘汰,但 2026 年的默认负载已从「偶尔 ollama run」变成「浏览器 + IDE + 8B 常驻 + Agent」。16GB 仍可胜任:8B 推理、API 为主、肯关标签。若你默认开 Claude Code / OpenHuman 且不想清场,16GB 会越来越像「入门档」而非「舒服档」。
24GB 能撑几年?
按当前模型节奏(8B–14B 主力、27B 试玩),24GB 大约 3–5 年仍是对齐「桌面 + 本地 Agent」的甜点位:能同时留 14B、嵌入模型和开发工具。再往上(32B+ 常驻)应规划 Mac Studio / 云 GPU,而不是指望 Mac mini 加内存(出厂不可扩)。
Ollama 和 MLX 哪个更省内存?
日常对话推理:Ollama 更省心。 GGUF + 常驻进程 footprint 可预测,与本文 Activity Monitor 读数一致。MLX 在加载、编译或与 Xcode 链路同跑时峰值更尖,平均不一定更高,但更容易瞬时顶满导致 Swap。建议:Ollama 做默认聊天/RAG;MLX 放批处理或独享节点。
Mac mini 和 RTX 5060 谁更适合本地 AI?
文本 8B–14B、Claude Code、iOS 开发:M4 Mac mini(建议 24GB)更合适。 统一内存 + macOS 工具链是护城河。Stable Diffusion、70B 量化、游戏:RTX 5060 更合适,显存与 CUDA 生态无法被 Mac mini 替代。很多人最终是「Mac mini + RTX 或云 GPU」分工,而非二选一。
M4 Mac mini 16GB 跑 Qwen3 8B 够用吗?
够用。实测 13.2GB 已用、Swap 约 1.1GB、34 tok/s,内存压力黄色。能接受偶发卡顿可选 16GB;要零 Swap 桌面选 24GB(16.4GB 已用、37 tok/s)。
24GB 比 16GB 跑 Ollama 快多少?
同模型 qwen3:8b 仅快约 9%(34 vs 37 tok/s)。24GB 的核心价值是零 Swap、可叠 14B 与第二个小模型,不是裸算力翻倍。
Gemma 3 27B 能在 24GB Mac mini 上跑吗?
仅 ⚠️ 重度量化试玩;上下文稍长即 OOM。8B–14B 是 24GB 舒适区,27B 主力请 RTX 或云 GPU。
Mac Studio 值得为了 AI 加钱吗?
若你只是 8B–14B + 开发,M4 Mac mini 24GB 性价比更高。需要 64GB 统一内存、多路 14B/32B 或更重 MLX 流水线时,再考虑 Mac Studio;也可先用 Cloud Mac 验证内存曲线再决定是否上 Studio。
不确定买哪档内存怎么办?
按文内命令跑 8B + 14B 各 30 分钟,看 Swap 与内存压力。若还没有机器,可租用同配置 M4 Mac mini 云主机(24GB)部署 Ollama / OpenHuman,观察一周再下单实体机——通常比盲目加配或先买 RTX 更省。
实测数据可以复现吗?
可以。Ollama 0.12.x、相同 Chrome/IDE/微信场景下,绝对值可能差 ±10%,但16GB 有 Swap、24GB 零 Swap、14B 需 24GB 的趋势应一致。
经验分享
不确定内存档位?先跑一周再决定
用与正文相同的负载(Chrome、IDE、qwen3:8b / qwen3:14b)记录 Swap 与内存压力。若需要与生产一致的独享 macOS 环境做对照,ZavCloud 提供 M4 Mac mini 云主机,适合购买前验证。