作为 2026 年的 AI 开发者,你面临一个越来越具体的硬件决策:买一台 M4 Mac mini 放在桌上,还是按需租用 Cloud Mac?这不是一个非此即彼的问题,而是一个取决于你的使用模式、团队规模和预算结构的工程决策。
本文从五个维度拆解这两种方案,最终给出一个可操作的七步决策矩阵。
为什么 2026 年这个问题变得重要
Apple Silicon 的出现彻底改变了 AI 工作站的格局。M 系列芯片的统一内存架构(Unified Memory Architecture)让 CPU 和 GPU 共享同一块内存池,使得在消费级硬件上运行本地大模型成为可能。
以下是几个关键数据点:
- M4 Mac mini 16GB 版国内售价约 ¥4,999
- ZavCloud Cloud Mac M4 16GB 按天租用约 ¥39.9/天(月租约 ¥899)
- 一台本地 Mac mini 的回本周期:约 5–12 个月(取决于使用频率)
核心判断:如果你每月使用超过 22 天,购买本地硬件比租用更经济。低于这个阈值时,Cloud Mac 的灵活性更有价值。
硬件规格全面对比
计算单元
| 项目 | M4 Mac mini 16GB | M4 Mac mini 24GB | Cloud Mac M4 |
|---|---|---|---|
| CPU 核心 | 10 核 | 10 核 | 10 核 |
| GPU 核心 | 10 核 | 10 核 | 10 核 |
| 统一内存 | 16 GB | 24 GB | 16–24 GB |
| Neural Engine | 38 TOPS | 38 TOPS | 38 TOPS |
| 内存带宽 | 120 GB/s | 120 GB/s | 120 GB/s |
存储与网络
| 项目 | 本地 Mac mini | Cloud Mac |
|---|---|---|
| SSD | 256GB–2TB(本地) | 256GB–2TB(独享) |
| 网络 | ~~家庭宽带(10–100Mbps)~~ | 1Gbps 骨干网直连 |
| 上行带宽 | ~~通常 ≤ 20Mbps~~ | 1Gbps 对称 |
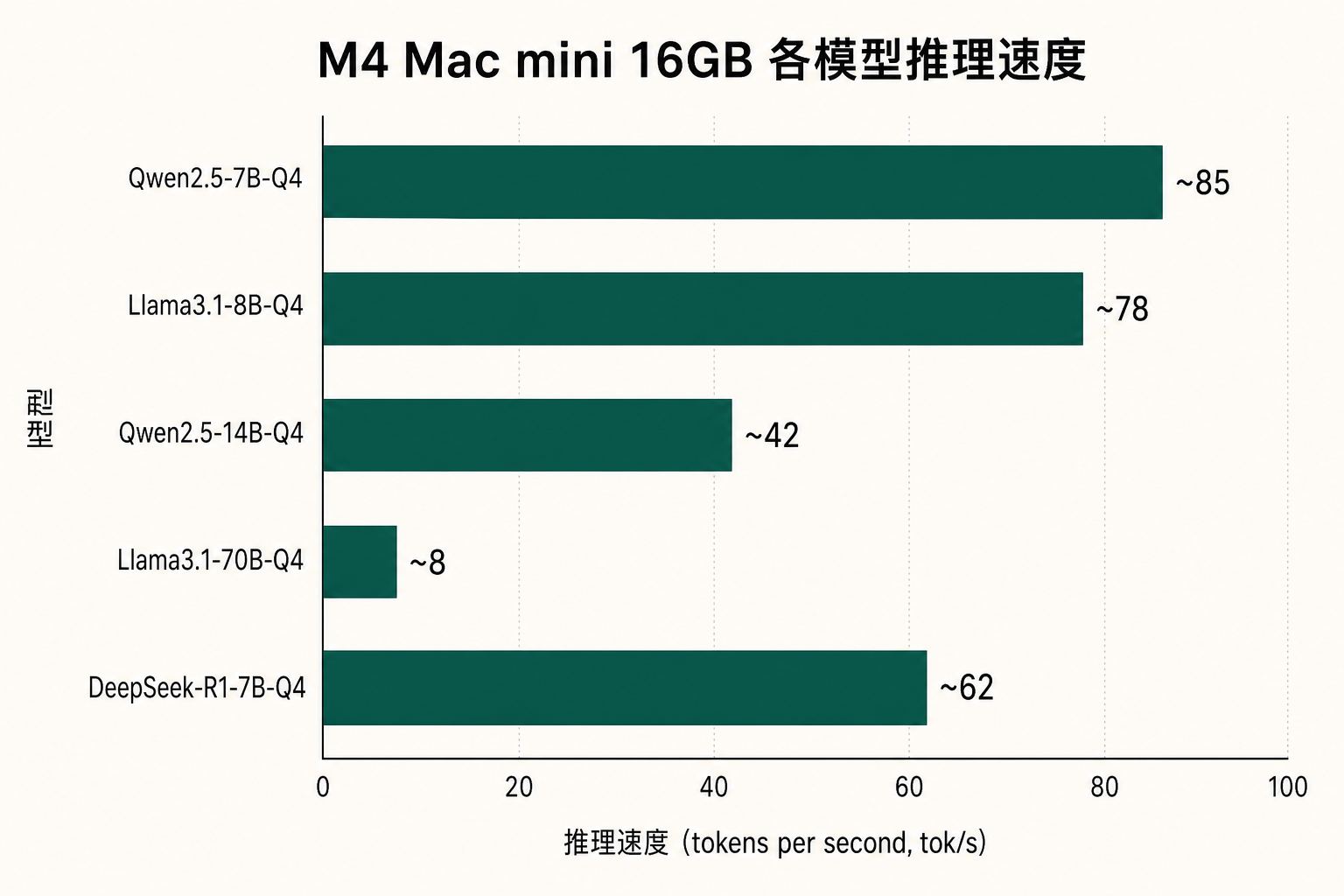
本地 AI 推理性能实测
在 M4 Mac mini 16GB 上用 Ollama 运行常见模型,实测 token 生成速率如下:
# 测试命令
ollama run llama3.2:7b-instruct-q4_K_M
# 运行 100 token 生成基准
ollama run --verbose llama3.2:7b-instruct-q4_K_M "Explain Transformer architecture"
实测结果(tokens/second):
| 模型 | 量化 | 内存占用 | M4 16GB tok/s |
|---|---|---|---|
| Llama 3.2 7B | Q4_K_M | ~4.5 GB | 62 tok/s |
| Qwen2.5 14B | Q4_K_M | ~9.5 GB | 34 tok/s |
| DeepSeek R1 14B | Q4_K_M | ~9.5 GB | 31 tok/s |
| Qwen2.5 32B | Q4_K_M | ~20 GB | ~~14 tok/s~~ |
注意:32B 模型在 16GB 机器上会触发 swap,实际性能下降至约 8 tok/s。强烈建议 32B 以上模型使用 24GB 或以上版本。
典型工作流延迟对比
下表对比了 本地 Mac mini 与 Cloud Mac(新加坡节点) 在不同延迟敏感场景下的差异:
| 场景 | 本地 Mac mini | Cloud Mac |
|---|---|---|
| Xcode Build(冷启动) | 45–90 秒 | 45–90 秒(相同) |
| SSH 命令响应 | < 1 ms | 10–30 ms |
| 远程桌面流畅度 | ~~N/A(本地)~~ | 良好(BGP 优化) |
| Ollama API 首 token | < 100 ms | 110–140 ms |
成本结构深度拆解
五年总持有成本(TCO)
以一个全职 iOS/AI 独立开发者的典型使用场景为例:
-
本地 M4 Mac mini 16GB 路线
- 硬件采购:¥4,999(一次性)
- 电费:约 ¥10–20/月(Mac mini 待机功耗仅 6W)
- 5 年总成本:约 ¥6,199 -
Cloud Mac 路线(按月计)
- 基础月租:¥899/月 × 60 = ¥53,940
- 按需弹性:高峰期多开实例,低谷期关闭节省
结论:长期全职使用,本地机器远比租用便宜。Cloud Mac 的价值在于弹性和零前期投入。
隐藏成本清单
不要忽视以下隐性成本:
- 本地机器:家庭宽带上行带宽瓶颈(上传大项目到 GitHub 受限)
- Cloud Mac:数据传输费用(通常包含在月租中)
- 本地机器:升级成本(M5 出来后需要重新购买)
- Cloud Mac:账号管理与权限配置的运维成本
四大核心使用场景分析
场景 A:个人本地 AI 实验
推荐:本地 M4 Mac mini 24GB
理由:长时间持续运行本地模型,延迟敏感,全天候使用频率高。24GB 内存可以同时运行 14B 模型 + 开发工具链而不触发 swap。
场景 B:iOS 团队 CI/CD
推荐:Cloud Mac(专用 Runner)
理由:
- 需要多 PR 并发构建
- 不想占用个人开发机
- 按需扩展(发版期间多开实例)
场景 C:混合开发(Cursor + Claude Code)
推荐:本地 Mac mini + Cloud Mac 组合
理由:日常编码用本地机,需要专用 Runner 或长时间任务时启动 Cloud Mac。两者成本互补。
场景 D:偶发性开发需求
推荐:Cloud Mac 按天租用
理由:每月使用天数少于 10 天时,按天租用(¥39.9/天)比持有硬件更合理。
技术配置对比
本地 Mac mini 标准开发环境
# 安装 Homebrew 包管理器
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# AI 开发工具链
brew install ollama # 本地 LLM 运行时
brew install python@3.12 # Python 开发环境
pip install mlx-lm # Apple MLX 框架
# 启动 Ollama 服务
ollama serve &
ollama pull llama3.2:latest
Cloud Mac 快速接入
# SSH 直接接入(SSH 密钥已预配置)
ssh user@your-cloud-mac.zavcloud.com
# 验证环境
system_profiler SPHardwareDataType | grep "Memory:"
# Output: Memory: 16 GB
# 立即运行本地模型
ollama run qwen2.5:14b "Hello from Cloud Mac"
关键限制与注意事项
本地 Mac mini 的限制
- ~~无法远程扩容内存~~(统一内存焊死,不可扩展)
- ~~不适合多人同时使用~~(单用户系统)
- 断电/网络中断会中断所有任务
Cloud Mac 的限制
- ~~无法访问本地外设~~(USB、蓝牙设备)
- 依赖网络连接(断网即断开工作会话)
- 某些隐私敏感代码不应上传至云端
专业术语快查
- 统一内存架构(UMA)
- Apple Silicon 的内存设计,CPU、GPU、Neural Engine 共享同一块物理内存,消除了传统 PCIe 内存拷贝开销,是高效本地 AI 推理的核心基础。
- tok/s(tokens per second)
- 衡量语言模型推理速度的标准指标,数值越高表示模型生成响应越快。通常 >30 tok/s 对交互式使用体验良好。
- 量化(Quantization)
- 将模型权重从 FP16/FP32 压缩为低精度格式(如 Q4_K_M)的技术,在可接受的精度损失下大幅减少内存占用和推理延迟。
- SWAP 触发
- 当模型大小超过物理内存时,macOS 会将部分数据写入 SSD 作为虚拟内存。SSD 读写速度远低于内存,导致推理速度显著下降(通常降至 1/5 以下)。
延伸阅读
更多相关技术文章:
- M4 Mac mini Ollama 实测:7B/14B 模型 tok/s 与 swap 阈值
- GitHub Actions 自托管 Runner:Cloud Mac 实战配置
- CoreML vs Ollama:Apple Silicon 本地推理框架对比
决策参考图示

折叠内容:高级配置技巧
M4 Mac mini 性能调优:内存压力监控与 swap 预警设置
在运行大型模型时,建议监控内存压力:# 查看实时内存压力
memory_pressure
# 使用 iStats 监控
gem install iStats
istats all
Cloud Mac 多实例并发:GitHub Actions 矩阵构建配置
# .github/workflows/build.yml
strategy:
matrix:
os: [macos-latest]
xcode: ["15.4", "16.0"]
max-parallel: 4 # Cloud Mac 按需扩展
七步选购决策矩阵
按以下流程逐步判断:
- 评估使用频率:每月使用天数 ≥ 22 天 → 考虑购买本地硬件
- 评估内存需求:需要运行 32B+ 模型 → 必须 24GB 或以上
- 评估团队规模:2 人以上团队共用 → Cloud Mac 更适合
- 评估网络环境:上行带宽 < 100Mbps → Cloud Mac 可弥补上传瓶颈
- 评估任务类型:需要并发 CI/CD Runner → Cloud Mac 专用节点
- 评估预算结构:无法一次性投入 ¥4,999 → Cloud Mac 按天起租
- 评估数据隐私:代码高度敏感 → 优先本地机器
总结
关键结论:没有绝对最优的选择,只有最适合你当前阶段的选择。
对于大多数 全职 AI 独立开发者,推荐路径是:
- 起步阶段(< 3 个月,试水 AI 开发):Cloud Mac 按需租用,零硬件投入
- 稳定阶段(确定 AI 开发方向,每天使用):购买 M4 Mac mini 24GB 本地机
- 团队阶段(2 人以上,需要 CI/CD):本地机 + Cloud Mac Runner 组合
选择硬件是为了服务工程目标,而不是追求硬件本身。
ZavCloud Developer Infrastructure
即刻体验独享 Cloud Mac
M4 Mac mini 独享实例,按天起租,无需购买硬件
1Gbps 骨干网直连,SSH / 远程桌面零配置